Chapter 4: Crawling the Web and Extracting Data
Intro
Today’s session will be dedicated to getting data from the web. This process is also called scraping since we scrape data off from the surface (and remodel it for our purposes). The following picture shows you the web scraping cheat sheet that outlines the process of scraping the web. On the left side, you can see the first step in scraping the web which is requesting the information from the server. This is basically what is going under the hood when you make requests using a browser. The response is the website, usually stored in an XML document, which is then the starting point for your subsequent queries and data extraction.
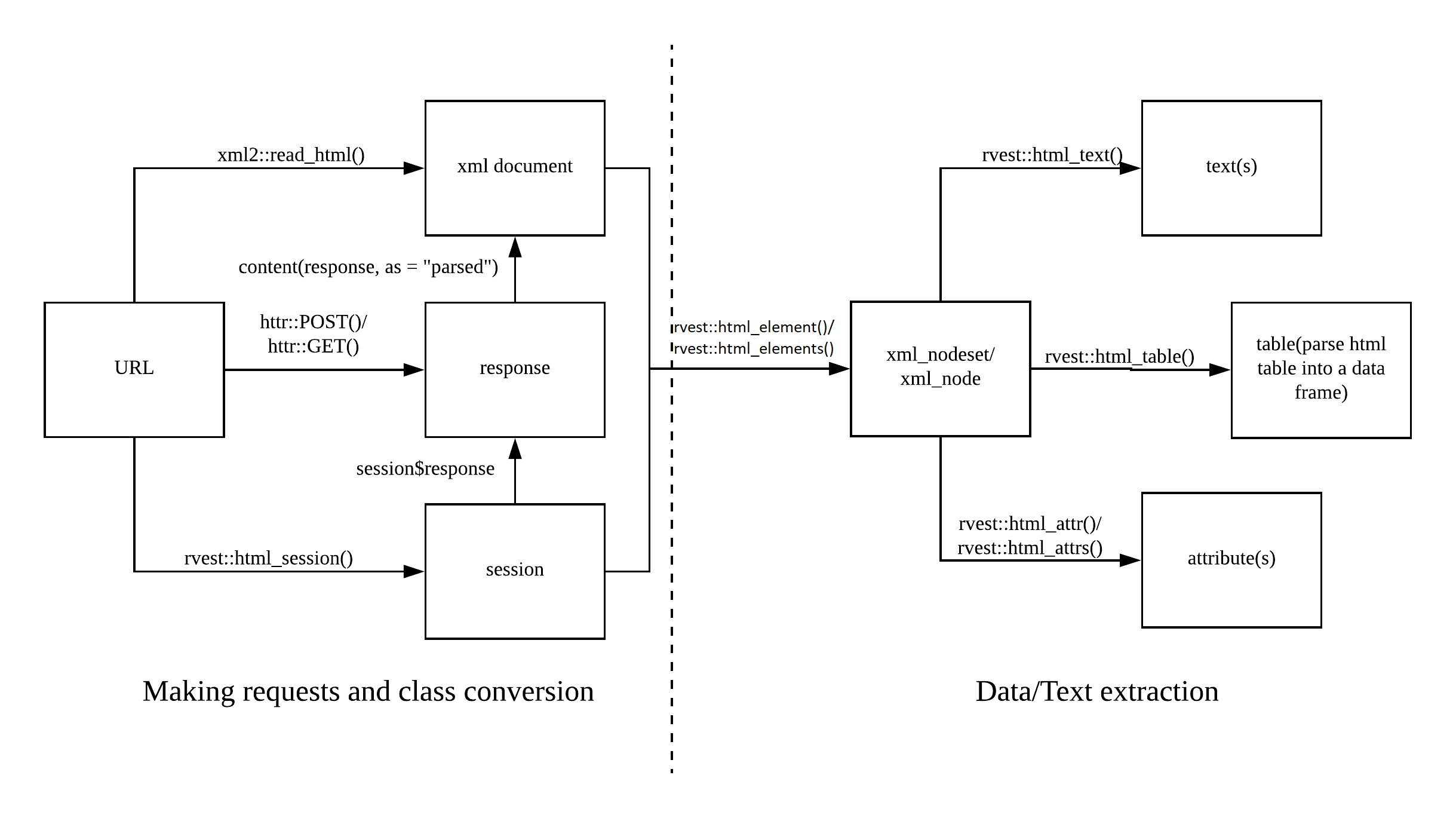
In the first part of this chapter, you will learn different techniques to get your hands on data. In particular, this will encompass making simple URL requests with read_html(), using session()s to navigate around on a web page, and submitting html_form()s to fill in forms on a web page. The second part will be dedicated to only choosing particular contents of the page.
Getting started with rvest
Making requests
The most basic form of making a request is by using read_html() from the xml2 package.
needs(httr, rvest, tidyverse)
page <- read_html("https://en.wikipedia.org/wiki/Tidyverse")
page |> str()List of 2
$ node:<externalptr>
$ doc :<externalptr>
- attr(*, "class")= chr [1:2] "xml_document" "xml_node"page |> as.character() |> write_lines("wiki.html")
#page |> html_text()This is perfectly fine for making requests to static pages where you do not need to take any further action. Sometimes, however, this is not enough, and you want to accept cookies or move on the page.
session()s
However, the slickest way to do this is by using a session(). In a session, R behaves like a normal browser, stores cookies, allows you to navigate between pages, by going session_forward() or session_back(), session_follow_link()s on the page itself or session_jump_to() a different URL, or submit form()s with session_submit().
First, you start the session by simply calling session().
my_session <- session("https://scrapethissite.com/")Some servers may not want robots to make requests and block you for this reason. To circumnavigate this, we can set a “user agent” in a session. The user agent contains data that the server receives from us when we make the request. Hence, by adapting it we can trick the server into thinking that we are humans instead of robots. Let’s check the current user agent first:
my_session$response$request$options$useragent[1] "libcurl/8.7.1 r-curl/6.0.1 httr/1.4.7"Not very human. We can set it to a common one using the httr package (which powers rvest).
user_a <- user_agent("Mozilla/5.0 (Macintosh; Intel Mac OS X 12_0_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36")
session_with_ua <- session("https://scrapethissite.com/", user_a)
session_with_ua$response$request$options$useragent[1] "Mozilla/5.0 (Macintosh; Intel Mac OS X 12_0_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36"You can check the response using session$response$status_code – 200 is good.
my_session$response$status_code[1] 200When you want to save a page from the session, do so using read_html().
page <- read_html(session_with_ua)If you want to open a new URL, use session_jump_to().
session_with_ua <- session_with_ua |>
session_jump_to("https://www.scrapethissite.com/pages/")
session_with_ua<session> https://www.scrapethissite.com/pages/
Status: 200
Type: text/html; charset=utf-8
Size: 10603You can also click buttons on the page using CSS selectors or XPATHs (more on them next session!):
session_with_ua <- session_with_ua |>
session_jump_to("https://www.scrapethissite.com/") |>
session_follow_link(css = ".btn-primary")Navigating to </lessons/>.session_with_ua<session> http://www.scrapethissite.com/lessons/sign-up/
Status: 200
Type: text/html; charset=utf-8
Size: 24168Wanna go back – session_back(); thereafter you can go session_forward(), too.
session_with_ua <- session_with_ua |>
session_back()
session_with_ua<session> https://www.scrapethissite.com/
Status: 200
Type: text/html; charset=utf-8
Size: 8117session_with_ua <- session_with_ua |>
session_forward()
session_with_ua<session> http://www.scrapethissite.com/lessons/sign-up/
Status: 200
Type: text/html; charset=utf-8
Size: 24168You can look at what your scraper has done with session_history().
session_with_ua |> session_history() https://www.scrapethissite.com/
https://www.scrapethissite.com/pages/
https://www.scrapethissite.com/
- http://www.scrapethissite.com/lessons/sign-up/Exercise
- Start a session with the tidyverse Wikipedia page. Adapt your user agent to some sort of different value. Proceed to Hadley Wickham’s page. Go back. Go forth. Jump to Pierre Bourdieu’s Wikipedia page. Check the
session_history()to see if it has worked.
Solution. Click to expand!
needs(tidyverse, rvest, httr)
tidyverse_wiki <- "https://en.wikipedia.org/wiki/Tidyverse"
pierre_wiki <- "https://en.wikipedia.org/wiki/Pierre_Bourdieu"
user_agent <- user_agent("Hi, I'm Felix and I'm trying to steal your data.") #can be changedwiki_session <- session(tidyverse_wiki, user_agent)
wiki_session_jumped <- wiki_session |>
session_jump_to(tidyverse_wiki) |>
session_back() |>
session_forward() |>
session_jump_to(pierre_wiki)
wiki_session_jumped |> session_history()Forms
Sometimes we also want to provide certain input, e.g., to provide login credentials or to scrape a website more systematically. That information is usually provided using so-called forms. A <form> element can contain different other elements such as text fields or check boxes. Basically, we use html_form() to extract the form, html_form_set() to define what we want to submit, and html_form_submit() to finally submit it. For a basic example, we search for something on Google.
google <- read_html("http://www.google.com")
search <- html_form(google) |> pluck(1)
search |> str()List of 5
$ name : chr "f"
$ method : chr "GET"
$ action : chr "http://www.google.com/search"
$ enctype: chr "form"
$ fields :List of 10
..$ ie :List of 4
.. ..$ type : chr "hidden"
.. ..$ name : chr "ie"
.. ..$ value: chr "ISO-8859-1"
.. ..$ attr :List of 3
.. .. ..$ name : chr "ie"
.. .. ..$ value: chr "ISO-8859-1"
.. .. ..$ type : chr "hidden"
.. ..- attr(*, "class")= chr "rvest_field"
..$ hl :List of 4
.. ..$ type : chr "hidden"
.. ..$ name : chr "hl"
.. ..$ value: chr "de"
.. ..$ attr :List of 3
.. .. ..$ value: chr "de"
.. .. ..$ name : chr "hl"
.. .. ..$ type : chr "hidden"
.. ..- attr(*, "class")= chr "rvest_field"
..$ source:List of 4
.. ..$ type : chr "hidden"
.. ..$ name : chr "source"
.. ..$ value: chr "hp"
.. ..$ attr :List of 3
.. .. ..$ name : chr "source"
.. .. ..$ type : chr "hidden"
.. .. ..$ value: chr "hp"
.. ..- attr(*, "class")= chr "rvest_field"
..$ biw :List of 4
.. ..$ type : chr "hidden"
.. ..$ name : chr "biw"
.. ..$ value: NULL
.. ..$ attr :List of 2
.. .. ..$ name: chr "biw"
.. .. ..$ type: chr "hidden"
.. ..- attr(*, "class")= chr "rvest_field"
..$ bih :List of 4
.. ..$ type : chr "hidden"
.. ..$ name : chr "bih"
.. ..$ value: NULL
.. ..$ attr :List of 2
.. .. ..$ name: chr "bih"
.. .. ..$ type: chr "hidden"
.. ..- attr(*, "class")= chr "rvest_field"
..$ q :List of 4
.. ..$ type : chr "text"
.. ..$ name : chr "q"
.. ..$ value: chr ""
.. ..$ attr :List of 8
.. .. ..$ class : chr "lst"
.. .. ..$ style : chr "margin:0;padding:5px 8px 0 6px;vertical-align:top;color:#000"
.. .. ..$ autocomplete: chr "off"
.. .. ..$ value : chr ""
.. .. ..$ title : chr "Google Suche"
.. .. ..$ maxlength : chr "2048"
.. .. ..$ name : chr "q"
.. .. ..$ size : chr "57"
.. ..- attr(*, "class")= chr "rvest_field"
..$ btnG :List of 4
.. ..$ type : chr "submit"
.. ..$ name : chr "btnG"
.. ..$ value: chr "Google Suche"
.. ..$ attr :List of 4
.. .. ..$ class: chr "lsb"
.. .. ..$ value: chr "Google Suche"
.. .. ..$ name : chr "btnG"
.. .. ..$ type : chr "submit"
.. ..- attr(*, "class")= chr "rvest_field"
..$ btnI :List of 4
.. ..$ type : chr "submit"
.. ..$ name : chr "btnI"
.. ..$ value: chr "Auf gut GlÃck!"
.. ..$ attr :List of 5
.. .. ..$ class: chr "lsb"
.. .. ..$ id : chr "tsuid_HvFjZ8yKOc-Sxc8Ps-T42A8_1"
.. .. ..$ value: chr "Auf gut GlÃck!"
.. .. ..$ name : chr "btnI"
.. .. ..$ type : chr "submit"
.. ..- attr(*, "class")= chr "rvest_field"
..$ iflsig:List of 4
.. ..$ type : chr "hidden"
.. ..$ name : chr "iflsig"
.. ..$ value: chr "AL9hbdgAAAAAZ2P_LsCphGzJX_OBLqUcvOTeUILteWpi"
.. ..$ attr :List of 3
.. .. ..$ value: chr "AL9hbdgAAAAAZ2P_LsCphGzJX_OBLqUcvOTeUILteWpi"
.. .. ..$ name : chr "iflsig"
.. .. ..$ type : chr "hidden"
.. ..- attr(*, "class")= chr "rvest_field"
..$ gbv :List of 4
.. ..$ type : chr "hidden"
.. ..$ name : chr "gbv"
.. ..$ value: chr "1"
.. ..$ attr :List of 4
.. .. ..$ id : chr "gbv"
.. .. ..$ name : chr "gbv"
.. .. ..$ type : chr "hidden"
.. .. ..$ value: chr "1"
.. ..- attr(*, "class")= chr "rvest_field"
- attr(*, "class")= chr "rvest_form"search_something <- search |> html_form_set(q = "something")
resp <- html_form_submit(search_something, submit = "btnG")
read_html(resp){html_document}
<html lang="de">
[1] <head>\n<meta http-equiv="Content-Type" content="text/html; charset=UTF-8 ...
[2] <body jsmodel="hspDDf ">\n<header id="hdr"><script nonce="xJ8xAZHddf-g3l- ...vals <- list(q = "web scraping", hl = "fr")
search_1 <- search |> html_form_set(!!!vals)
search_2 <- search |> html_form_set(q = "web scraping", hl = "fr")
resp <- html_form_submit(search_1)
read_html(resp){html_document}
<html lang="fr-DE">
[1] <head>\n<meta http-equiv="Content-Type" content="text/html; charset=UTF-8 ...
[2] <body jsmodel="hspDDf ">\n<header id="hdr"><script nonce="ZVuXvunLhu-hdxa ...If you are working with a session, the workflow is as follows:
- Extract the form.
- Set it.
- Start your session on the page with the form.
- Submit the form using
session_submit().
google_form <- read_html("http://www.google.com") |>
html_form() |>
pluck(1) #another way to do [[1]]
search_something <- google_form |> html_form_set(q = "something")
google_session <- session("http://www.google.com") |>
session_submit(search_something, submit = "btnG")
google_session |>
read_html(){html_document}
<html lang="de">
[1] <head>\n<meta http-equiv="Content-Type" content="text/html; charset=UTF-8 ...
[2] <body jsmodel="hspDDf ">\n<header id="hdr"><script nonce="RoMxLlFxe39G-IA ...Exercise
- Start a session on “https://www.scrapethissite.com/pages/forms/”, fill out, and submit the form to search for a Hockey team called Toronto Maple Leafs. Store the resulting output in “base_session”.
You can check your code by looking at the output of base_session |> read_html() |> html_table() |> pluck(1) and checking whether there are only Maple Leaf entries.
Solution. Click to expand!
url <- "https://www.scrapethissite.com/pages/forms/"
search_form <- read_html(url) |>
html_form() |>
pluck(1) #extract
set_form <- search_form |>
html_form_set(q = "Toronto Maple Leafs") #set login form
base_session <- session(url) |>
session_submit(set_form)
base_session |>
read_html() |>
html_table() |>
pluck(1)Scraping hacks
Some web pages are a bit fancier than the ones we have looked at so far (i.e., they use JavaScript). rvest works nicely for static web pages, but for more advanced ones you need different tools such as selenium – see chapter 7.
A web page may sometimes give you time-outs (i.e., it doesn’t respond within a given time). This can break your loop. Wrapping your code in safely() or insistently() from the purrr package might help. The former moves on and notes down what has gone wrong, the latter keeps sending requests until it has been successful. They both work easiest if you put your scraping code in functions and wrap those with either insistently() or safely().
Sometimes a web page keeps blocking you. Consider using a proxy server.
my_proxy <- httr::use_proxy(url = "http://example.com",
user_name = "myusername",
password = "mypassword",
auth = "one of basic, digest, digest_ie, gssnegotiate, ntlm, any")
my_session <- session("https://scrapethissite.com/", my_proxy)Find more useful information – including the stuff we just described – and links on this GitHub page.
Extracting Data
In the prior section you learned how to make calls to web pages and get responses. Now it will be all about how you can extract content from web pages in a structured way. The (in our opinion) easiest way to achieve that is by harnessing the way the web is written.
Before we start to extract data from the web, we will briefly touch upon how the web is written. This is since we will harness this structure to extract content in an automated manner. Basic commands will be shown thereafter.
#install.packages("needs")
needs::needs(janitor, polite, rvest, tidyverse)HTML 101
Web content is usually written in HTML (Hyper Text Markup Language). An HTML document is comprised of elements that are letting its content appear in a certain way.
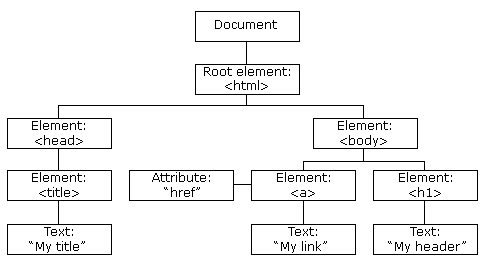
The way these elements look is defined by so-called tags.

The opening tag is the name of the element (p in this case) in angle brackets, and the closing tag is the same with a forward slash before the name. p stands for a paragraph element and would look like this (since RMarkdown can handle HTML tags, the second line will showcase how it would appear on a web page):
<p> My cat is very grumpy. <p/>
My cat is very grumpy.
The <p> tag makes sure that the text is standing by itself and that a line break is included thereafter:
<p>My cat is very grumpy</p>. And so is my dog. would look like this:
My cat is very grumpy
. And so is my dog.
There do exist many types of tags indicating different kinds of elements (about 100). Every page’s content must be in an <html> element with two children <head> and <body>. The former contains the page title and some metadata, the latter the contents you are seeing in your browser. So-called block tags, e.g., <h1> (heading 1), <p> (paragraph), or <ol> (ordered list), structure the page. Inline tags (<b> – bold, <a> – link) format text inside block tags.
You can nest elements, e.g., if you want to make certain things bold, you can wrap text in <b>:
<p>My cat is <b> very </b> grumpy</p>
My cat is very grumpy
Then, the <b> element is considered the child of the <p> element.
Elements can also bear attributes:

Those attributes will not appear in the actual content. Moreover, they are super-handy for us as scrapers. Here, class is the attribute name and "editor-note" the value. Another important attribute is id. Combined with CSS, they control the appearance of the element on the actual page. A class can be used by multiple HTML elements whereas an id is unique.
Extracting content in rvest
To scrape the web, the first step is to simply read in the web page. rvest then stores it in the XML format – just another format to store information. For this, we use rvest’s read_html() function.
To demonstrate the usage of CSS selectors, I create my own, basic web page using the rvest function minimal_html():
basic_html <- minimal_html('
<html>
<head>
<title>Page title</title>
</head>
<body>
<h1 id="first">A heading</h1>
<p class="paragraph">Some text & <b>some bold text.</b></p>
<a> Some more <i> italicized text which is not in a paragraph. </i> </a>
<a class="paragraph">even more text & <i>some italicized text.</i></p>
<a id="link" href="www.nyt.com"> The New York Times </a>
</body>
')
basic_html{html_document}
<html>
[1] <head>\n<meta http-equiv="Content-Type" content="text/html; charset=UTF-8 ...
[2] <body>\n <h1 id="first">A heading</h1>\n <p class="paragraph">Some ...#https://htmledit.squarefree.comCSS is the abbreviation for cascading style sheets and is used to define the visual styling of HTML documents. CSS selectors map elements in the HTML code to the relevant styles in the CSS. Hence, they define patterns that allow us to easily select certain elements on the page. CSS selectors can be used in conjunction with the rvest function html_elements() which takes as arguments the read-in page and a CSS selector. Alternatively, you can also provide an XPath which is usually a bit more complicated and will not be covered in this tutorial.
pselects all<p>elements.
basic_html |> html_elements(css = "p"){xml_nodeset (1)}
[1] <p class="paragraph">Some text & <b>some bold text.</b></p>.titleselects all elements that are ofclass“title”
basic_html |> html_elements(css = ".title"){xml_nodeset (0)}There are no elements of class “title”. But some of class “paragraph”.
basic_html |> html_elements(css = ".paragraph"){xml_nodeset (2)}
[1] <p class="paragraph">Some text & <b>some bold text.</b></p>
[2] <a class="paragraph">even more text & <i>some italicized text.</i>\n ...p.paragraphanalogously takes every<p>element which is ofclass“paragraph”.
basic_html |> html_elements(css = "p.paragraph"){xml_nodeset (1)}
[1] <p class="paragraph">Some text & <b>some bold text.</b></p>#linkscrapes elements that are ofid“link”
basic_html |> html_elements(css = "#link"){xml_nodeset (1)}
[1] <a id="link" href="www.nyt.com"> The New York Times </a>You can also connect children with their parents by using the combinator. For instance, to extract the italicized text from “a.paragraph,” I can do “a.paragraph i”.
basic_html |> html_elements(css = "a.paragraph i"){xml_nodeset (1)}
[1] <i>some italicized text.</i>You can also look at the children by using html_children():
basic_html |> html_elements(css = "a.paragraph") |> html_children(){xml_nodeset (1)}
[1] <i>some italicized text.</i>read_html("https://rvest.tidyverse.org") |>
html_elements("#installation , p"){xml_nodeset (8)}
[1] <p>rvest helps you scrape (or harvest) data from web pages. It is designe ...
[2] <p>If you’re scraping multiple pages, I highly recommend using rvest in c ...
[3] <h2 id="installation">Installation<a class="anchor" aria-label="anchor" h ...
[4] <p>If the page contains tabular data you can convert it directly to a dat ...
[5] <p></p>
[6] <p>Developed by <a href="https://hadley.nz" class="external-link">Hadley ...
[7] <p></p>
[8] <p>Site built with <a href="https://pkgdown.r-lib.org/" class="external-l ...Unfortunately, web pages in the wild are usually not as easily readable as the small example one I came up with. Hence, I would recommend you to use the SelectorGadget – just drag it into your bookmarks list.
Its usage could hardly be simpler:
- Activate it – i.e., click on the bookmark.
- Click on the content you want to scrape – the things the CSS selector selects will appear green.
- Click on the green things that you don’t want – they will turn red; click on what’s not green yet but what you want – it will turn green.
- copy the CSS selector the gadget provides you with and paste it into the
html_elements()function.
read_html("https://en.wikipedia.org/wiki/Hadley_Wickham") |>
html_elements(css = "p:nth-child(4)") |>
html_text()character(0)Tying it Together: Scraping HTML pages with rvest
So far, I have shown you how HTML is written and how to select elements. However, what we want to achieve is extracting the data the elements contained in a proper format and storing it in some sort of tibble. Therefore, we need functions that allow us to grab the data.
The following overview taken from the web scraping cheatsheet shows you the basic “flow” of scraping web pages plus the corresponding functions. In this tutorial, I will limit myself to rvest functions. Those are of course perfectly compatible with things, for instance, RSelenium, as long as you feed the content in XML format (i.e., by using read_html()).
In the prior chapter, I have introduced you to acquiring the contents of singular pages. Given that you now know how to choose the content you want, all that you are lacking for successful scraping is the tools to extract these contents in a proper format.
html_text() and html_text2()
Extracting text from HTML is easy. You use html_text() or html_text2(). The former is faster but will give you not-so-nice results. The latter will give you the text like it would be returned in a web browser.
The following example is taken from the documentation
# To understand the difference between html_text() and html_text2()
# take the following html:
html <- minimal_html(
"<p>This is a paragraph.
This is another sentence.<br>This should start on a new line<p/>"
)# html_text() returns the raw underlying text, which includes white space
# that would be ignored by a browser, and ignores the <br>
html |> html_element("p") |> html_text() |> writeLines()This is a paragraph.
This is another sentence.This should start on a new line# html_text2() simulates what a browser would display. Non-significant
# white space is collapsed, and <br> is turned into a line break
html |> html_element("p") |> html_text2() |> writeLines()This is a paragraph. This is another sentence.
This should start on a new lineA “real example” would then look like this:
us_senators <- read_html("https://en.wikipedia.org/wiki/List_of_current_United_States_senators")
text <- us_senators |>
html_elements(css = "p:nth-child(6)") |>
html_text2()Extracting tables
The general output format we strive for is a tibble. Oftentimes, data is already stored online in a table format, basically ready for us to analyze them. In the next example, I want to get a table from the Wikipedia page that contains the senators of different States in the United States I have used before. For this first, basic example, I do not use selectors for extracting the right table. You can use rvest::html_table(). It will give you a list containing all tables on this particular page. We can inspect it using str() which returns an overview of the list and the tibbles it contains.
tables <- us_senators |>
html_table()
str(tables)List of 26
$ : tibble [4 × 3] (S3: tbl_df/tbl/data.frame)
..$ Affiliation: chr [1:4] "" "" "" "Total"
..$ Affiliation: chr [1:4] "Republican Party" "Democratic Party" "Independent" "Total"
..$ Members : int [1:4] 49 47 4 100
$ : tibble [11 × 1] (S3: tbl_df/tbl/data.frame)
..$ X1: chr [1:11] "This article is part of a series on the" "United States Senate" "Great Seal of the United States Senate" "History of the United States Senate" ...
$ : tibble [2 × 5] (S3: tbl_df/tbl/data.frame)
..$ Office : chr [1:2] "President of the Senate[a]" "President pro tempore"
..$ Party : chr [1:2] "Democratic" "Democratic"
..$ Officer: chr [1:2] "Kamala Harris" "Patty Murray"
..$ State : chr [1:2] "CA[b]" "WA"
..$ Since : chr [1:2] "January 20, 2021" "January 3, 2023Party dean since September 29, 2023"
$ : tibble [14 × 4] (S3: tbl_df/tbl/data.frame)
..$ Office : chr [1:14] "Senate Majority LeaderChair of the Senate Democratic Caucus" "Senate Majority Whip" "Chair of the Senate Democratic Policy and Communications Committee" "Chair of the Senate Democratic Steering Committee" ...
..$ Officer: chr [1:14] "Chuck Schumer" "Dick Durbin" "Debbie Stabenow" "Amy Klobuchar" ...
..$ State : chr [1:14] "NY" "IL" "MI" "MN" ...
..$ Since : chr [1:14] "January 20, 2021Party leader since January 3, 2017" "January 20, 2021Party whip since January 3, 2005" "January 3, 2017" "January 3, 2017" ...
$ : tibble [9 × 4] (S3: tbl_df/tbl/data.frame)
..$ Office : chr [1:9] "Senate Minority Leader" "Senate Minority Whip" "Chair of the Senate Republican Conference" "Chair of the Senate Republican Policy Committee" ...
..$ Officer: chr [1:9] "Mitch McConnell" "John Thune" "John Barrasso" "Joni Ernst" ...
..$ State : chr [1:9] "KY" "SD" "WY" "IA" ...
..$ Since : chr [1:9] "January 20, 2021Party leader since January 3, 2007" "January 20, 2021Party whip since January 3, 2019" "January 3, 2019" "January 3, 2023" ...
$ : tibble [100 × 12] (S3: tbl_df/tbl/data.frame)
..$ State : chr [1:100] "Alabama" "Alabama" "Alaska" "Alaska" ...
..$ Portrait : logi [1:100] NA NA NA NA NA NA ...
..$ Senator : chr [1:100] "Tommy Tuberville" "Katie Britt" "Lisa Murkowski" "Dan Sullivan" ...
..$ Party : logi [1:100] NA NA NA NA NA NA ...
..$ Party : chr [1:100] "Republican" "Republican" "Republican" "Republican" ...
..$ Born : chr [1:100] "(1954-09-18) September 18, 1954 (age 70)" "(1982-02-02) February 2, 1982 (age 42)" "(1957-05-22) May 22, 1957 (age 67)" "(1964-11-13) November 13, 1964 (age 60)" ...
..$ Occupation(s) : chr [1:100] "Investment management firm partner\nCollege football coach" "Alabama Wildlife Federation Board Member\nBusiness Council of Alabama President and CEO \nCampaign manager\nLaw"| __truncated__ "Lawyer" "Assistant Secretary of State for Economic and Business Affairs\nLawyer\nU.S. Marine Corps officer" ...
..$ Previous electiveoffice(s): chr [1:100] "None" "None" "Alaska House of Representatives" "Alaska Attorney General" ...
..$ Education : chr [1:100] "Southern Arkansas University (BS)" "University of Alabama (BS, JD)" "Georgetown University (AB)Willamette University (JD)" "Harvard University (AB)Georgetown University (MS, JD)" ...
..$ Assumed office : chr [1:100] "January 3, 2021" "January 3, 2023" "December 20, 2002[c]" "January 3, 2015" ...
..$ Class : chr [1:100] "2026Class 2" "2028Class 3" "2028Class 3" "2026Class 2" ...
..$ Residence[6] : chr [1:100] "Auburn[7]" "Montgomery" "Girdwood" "Anchorage" ...
$ : tibble [3 × 3] (S3: tbl_df/tbl/data.frame)
..$ vteCurrent United States senators: chr [1:3] "President: ▌ Kamala Harris (D) ‧ President pro tempore: ▌ Patty Murray (D)" "AL: ▌ Tuberville (R)⎣ ▌ Britt (R)\nAK: ▌ Murkowski (R)⎣ ▌ Sullivan (R)\nAZ: ▌ Sinema (I)⎣ ▌ Kelly (D)\nAR: ▌ Bo"| __truncated__ "▌ Republican: 49\n▌ Democratic: 47\n▌ Independent: 4"
..$ vteCurrent United States senators: chr [1:3] "President: ▌ Kamala Harris (D) ‧ President pro tempore: ▌ Patty Murray (D)" "AL: ▌ Tuberville (R)⎣ ▌ Britt (R)\nAK: ▌ Murkowski (R)⎣ ▌ Sullivan (R)\nAZ: ▌ Sinema (I)⎣ ▌ Kelly (D)\nAR: ▌ Bo"| __truncated__ "▌ Republican: 49\n▌ Democratic: 47\n▌ Independent: 4"
..$ vteCurrent United States senators: chr [1:3] "President: ▌ Kamala Harris (D) ‧ President pro tempore: ▌ Patty Murray (D)" "" "▌ Republican: 49\n▌ Democratic: 47\n▌ Independent: 4"
$ : tibble [4 × 6] (S3: tbl_df/tbl/data.frame)
..$ vteLeadership of the United States Senate: chr [1:4] "President: Kamala Harris (D)President pro tempore: Patty Murray (D)" "Majority (Democratic)Minority (Republican)\nChuck Schumer (Leader and Caucus Chair)\nDick Durbin (Whip)\nDebbie"| __truncated__ "Majority (Democratic)" "Chuck Schumer (Leader and Caucus Chair)\nDick Durbin (Whip)\nDebbie Stabenow (Policy/Communications Committee C"| __truncated__
..$ vteLeadership of the United States Senate: chr [1:4] "President: Kamala Harris (D)President pro tempore: Patty Murray (D)" "Majority (Democratic)Minority (Republican)\nChuck Schumer (Leader and Caucus Chair)\nDick Durbin (Whip)\nDebbie"| __truncated__ "Minority (Republican)" "Mitch McConnell (Leader)\nJohn Thune (Whip)\nJohn Barrasso (Conference Chair)\nJoni Ernst (Policy Committee Cha"| __truncated__
..$ : chr [1:4] NA "Majority (Democratic)" NA NA
..$ : chr [1:4] NA "Minority (Republican)" NA NA
..$ : chr [1:4] NA "Chuck Schumer (Leader and Caucus Chair)\nDick Durbin (Whip)\nDebbie Stabenow (Policy/Communications Committee C"| __truncated__ NA NA
..$ : chr [1:4] NA "Mitch McConnell (Leader)\nJohn Thune (Whip)\nJohn Barrasso (Conference Chair)\nJoni Ernst (Policy Committee Cha"| __truncated__ NA NA
$ : tibble [2 × 2] (S3: tbl_df/tbl/data.frame)
..$ X1: chr [1:2] "Majority (Democratic)" "Chuck Schumer (Leader and Caucus Chair)\nDick Durbin (Whip)\nDebbie Stabenow (Policy/Communications Committee C"| __truncated__
..$ X2: chr [1:2] "Minority (Republican)" "Mitch McConnell (Leader)\nJohn Thune (Whip)\nJohn Barrasso (Conference Chair)\nJoni Ernst (Policy Committee Cha"| __truncated__
$ : tibble [3 × 6] (S3: tbl_df/tbl/data.frame)
..$ vteChairs and ranking members of United States Senate committees: chr [1:3] "Chairs (Democratic)Ranking Members (Republican)\nAging (Special): Bob Casey\nAgriculture, Nutrition and Forestr"| __truncated__ "Chairs (Democratic)" "Aging (Special): Bob Casey\nAgriculture, Nutrition and Forestry: Debbie Stabenow\nAppropriations: Patty Murray\"| __truncated__
..$ vteChairs and ranking members of United States Senate committees: chr [1:3] "Chairs (Democratic)Ranking Members (Republican)\nAging (Special): Bob Casey\nAgriculture, Nutrition and Forestr"| __truncated__ "Ranking Members (Republican)" "Aging (Special): Mike Braun\nAgriculture, Nutrition and Forestry: John Boozman\nAppropriations: Susan Collins\n"| __truncated__
..$ : chr [1:3] "Chairs (Democratic)" NA NA
..$ : chr [1:3] "Ranking Members (Republican)" NA NA
..$ : chr [1:3] "Aging (Special): Bob Casey\nAgriculture, Nutrition and Forestry: Debbie Stabenow\nAppropriations: Patty Murray\"| __truncated__ NA NA
..$ : chr [1:3] "Aging (Special): Mike Braun\nAgriculture, Nutrition and Forestry: John Boozman\nAppropriations: Susan Collins\n"| __truncated__ NA NA
$ : tibble [2 × 2] (S3: tbl_df/tbl/data.frame)
..$ X1: chr [1:2] "Chairs (Democratic)" "Aging (Special): Bob Casey\nAgriculture, Nutrition and Forestry: Debbie Stabenow\nAppropriations: Patty Murray\"| __truncated__
..$ X2: chr [1:2] "Ranking Members (Republican)" "Aging (Special): Mike Braun\nAgriculture, Nutrition and Forestry: John Boozman\nAppropriations: Susan Collins\n"| __truncated__
$ : tibble [50 × 38] (S3: tbl_df/tbl/data.frame)
..$ vteUnited States Congress: chr [1:50] "House of Representatives\nSenate\nJoint session\n(117th ← 118th → 119th)\nLists of United States Congress" "Members and leadersMembershipMembers\nBy length of service\nBy shortness of service\nYoungest members\nNon-voti"| __truncated__ "Members and leaders" "MembershipMembers\nBy length of service\nBy shortness of service\nYoungest members\nNon-voting members\nUnseate"| __truncated__ ...
..$ vteUnited States Congress: chr [1:50] "House of Representatives\nSenate\nJoint session\n(117th ← 118th → 119th)\nLists of United States Congress" "Members and leadersMembershipMembers\nBy length of service\nBy shortness of service\nYoungest members\nNon-voti"| __truncated__ "Members and leaders" "MembershipMembers\nBy length of service\nBy shortness of service\nYoungest members\nNon-voting members\nUnseate"| __truncated__ ...
..$ : chr [1:50] NA "Members and leaders" NA "Membership" ...
..$ : chr [1:50] NA "Members and leaders" NA "Members\nBy length of service\nBy shortness of service\nYoungest members\nNon-voting members\nUnseated membersS"| __truncated__ ...
..$ : chr [1:50] NA "MembershipMembers\nBy length of service\nBy shortness of service\nYoungest members\nNon-voting members\nUnseate"| __truncated__ NA "Members" ...
..$ : chr [1:50] NA "MembershipMembers\nBy length of service\nBy shortness of service\nYoungest members\nNon-voting members\nUnseate"| __truncated__ NA "By length of service\nBy shortness of service\nYoungest members\nNon-voting members\nUnseated members" ...
..$ : chr [1:50] NA "Membership" NA "Senate" ...
..$ : chr [1:50] NA "Members\nBy length of service\nBy shortness of service\nYoungest members\nNon-voting members\nUnseated membersS"| __truncated__ NA "Members\nseniority\nDean\nFormer\nExpelled or censured\nClasses\nBorn outside the U.S.\nResigned\nAppointed\nSwitched parties" ...
..$ : chr [1:50] NA "Members" NA "House" ...
..$ : chr [1:50] NA "By length of service\nBy shortness of service\nYoungest members\nNon-voting members\nUnseated members" NA "Members\nseniority\nDean\nFormer\nExpelled, censured, and reprimanded\nServed a single term\nLost re-election i"| __truncated__ ...
..$ : chr [1:50] NA "Senate" NA "New members" ...
..$ : chr [1:50] NA "Members\nseniority\nDean\nFormer\nExpelled or censured\nClasses\nBorn outside the U.S.\nResigned\nAppointed\nSwitched parties" NA "90th (1967)\n91st (1969)\n92nd (1971)\n93rd (1973)\n94th (1975)\n95th (1977)\n96th (1979)\n97th (1981)\n98th (1"| __truncated__ ...
..$ : chr [1:50] NA "House" NA "Leaders" ...
..$ : chr [1:50] NA "Members\nseniority\nDean\nFormer\nExpelled, censured, and reprimanded\nServed a single term\nLost re-election i"| __truncated__ NA "Senate\nPresident\nlist\nPresident pro tempore\nlist\nLeaders\nDemocratic Caucus\nChair\nSecretary\nPolicy Comm"| __truncated__ ...
..$ : chr [1:50] NA "New members" NA "Senate" ...
..$ : chr [1:50] NA "90th (1967)\n91st (1969)\n92nd (1971)\n93rd (1973)\n94th (1975)\n95th (1977)\n96th (1979)\n97th (1981)\n98th (1"| __truncated__ NA "President\nlist\nPresident pro tempore\nlist\nLeaders\nDemocratic Caucus\nChair\nSecretary\nPolicy Committee Ch"| __truncated__ ...
..$ : chr [1:50] NA "Leaders" NA "House" ...
..$ : chr [1:50] NA "Senate\nPresident\nlist\nPresident pro tempore\nlist\nLeaders\nDemocratic Caucus\nChair\nSecretary\nPolicy Comm"| __truncated__ NA "Speaker\nlist\nLeaders\nBipartisan Legal Advisory Group\nDemocratic Caucus\nRepublican Conference" ...
..$ : chr [1:50] NA "Senate" NA "Districts" ...
..$ : chr [1:50] NA "President\nlist\nPresident pro tempore\nlist\nLeaders\nDemocratic Caucus\nChair\nSecretary\nPolicy Committee Ch"| __truncated__ NA "List\nApportionment\nGerrymandering" ...
..$ : chr [1:50] NA "House" NA "Groups" ...
..$ : chr [1:50] NA "Speaker\nlist\nLeaders\nBipartisan Legal Advisory Group\nDemocratic Caucus\nRepublican Conference" NA "Congressional caucus\nCaucuses of the United States CongressEthnic and racial\nAfrican-American members\nSenate"| __truncated__ ...
..$ : chr [1:50] NA "Districts" NA "Congressional caucus" ...
..$ : chr [1:50] NA "List\nApportionment\nGerrymandering" NA "Caucuses of the United States Congress" ...
..$ : chr [1:50] NA "Groups" NA "Ethnic and racial" ...
..$ : chr [1:50] NA "Congressional caucus\nCaucuses of the United States CongressEthnic and racial\nAfrican-American members\nSenate"| __truncated__ NA "African-American members\nSenate\nHouse\nBlack Caucus\nArab and Middle Eastern members\nAsian Pacific American "| __truncated__ ...
..$ : chr [1:50] NA "Congressional caucus" NA "Gender and sexual identity" ...
..$ : chr [1:50] NA "Caucuses of the United States Congress" NA "LGBT members\nEquality Caucus\nWomen\nSenate\nHouse\nIssues Caucus\ncurrent House" ...
..$ : chr [1:50] NA "Ethnic and racial" NA "Occupation" ...
..$ : chr [1:50] NA "African-American members\nSenate\nHouse\nBlack Caucus\nArab and Middle Eastern members\nAsian Pacific American "| __truncated__ NA "Physicians" ...
..$ : chr [1:50] NA "Gender and sexual identity" NA "Religion" ...
..$ : chr [1:50] NA "LGBT members\nEquality Caucus\nWomen\nSenate\nHouse\nIssues Caucus\ncurrent House" NA "Buddhist members\nHindu members\nJewish members\nMormon (LDS) members\nMuslim members\nQuaker members\nSikh members" ...
..$ : chr [1:50] NA "Occupation" NA "Related" ...
..$ : chr [1:50] NA "Physicians" NA "By length of service historically\nCurrent members by wealth\nFrom multiple states\nDied in office\n1790–1899\n"| __truncated__ ...
..$ : chr [1:50] NA "Religion" NA NA ...
..$ : chr [1:50] NA "Buddhist members\nHindu members\nJewish members\nMormon (LDS) members\nMuslim members\nQuaker members\nSikh members" NA NA ...
..$ : chr [1:50] NA "Related" NA NA ...
..$ : chr [1:50] NA "By length of service historically\nCurrent members by wealth\nFrom multiple states\nDied in office\n1790–1899\n"| __truncated__ NA NA ...
$ : tibble [17 × 34] (S3: tbl_df/tbl/data.frame)
..$ Members and leaders: chr [1:17] "MembershipMembers\nBy length of service\nBy shortness of service\nYoungest members\nNon-voting members\nUnseate"| __truncated__ "Membership" "Members" "Senate" ...
..$ Members and leaders: chr [1:17] "MembershipMembers\nBy length of service\nBy shortness of service\nYoungest members\nNon-voting members\nUnseate"| __truncated__ "Members\nBy length of service\nBy shortness of service\nYoungest members\nNon-voting members\nUnseated membersS"| __truncated__ "By length of service\nBy shortness of service\nYoungest members\nNon-voting members\nUnseated members" "Members\nseniority\nDean\nFormer\nExpelled or censured\nClasses\nBorn outside the U.S.\nResigned\nAppointed\nSwitched parties" ...
..$ : chr [1:17] "Membership" "Members" NA NA ...
..$ : chr [1:17] "Members\nBy length of service\nBy shortness of service\nYoungest members\nNon-voting members\nUnseated membersS"| __truncated__ "By length of service\nBy shortness of service\nYoungest members\nNon-voting members\nUnseated members" NA NA ...
..$ : chr [1:17] "Members" "Senate" NA NA ...
..$ : chr [1:17] "By length of service\nBy shortness of service\nYoungest members\nNon-voting members\nUnseated members" "Members\nseniority\nDean\nFormer\nExpelled or censured\nClasses\nBorn outside the U.S.\nResigned\nAppointed\nSwitched parties" NA NA ...
..$ : chr [1:17] "Senate" "House" NA NA ...
..$ : chr [1:17] "Members\nseniority\nDean\nFormer\nExpelled or censured\nClasses\nBorn outside the U.S.\nResigned\nAppointed\nSwitched parties" "Members\nseniority\nDean\nFormer\nExpelled, censured, and reprimanded\nServed a single term\nLost re-election i"| __truncated__ NA NA ...
..$ : chr [1:17] "House" "New members" NA NA ...
..$ : chr [1:17] "Members\nseniority\nDean\nFormer\nExpelled, censured, and reprimanded\nServed a single term\nLost re-election i"| __truncated__ "90th (1967)\n91st (1969)\n92nd (1971)\n93rd (1973)\n94th (1975)\n95th (1977)\n96th (1979)\n97th (1981)\n98th (1"| __truncated__ NA NA ...
..$ : chr [1:17] "New members" NA NA NA ...
..$ : chr [1:17] "90th (1967)\n91st (1969)\n92nd (1971)\n93rd (1973)\n94th (1975)\n95th (1977)\n96th (1979)\n97th (1981)\n98th (1"| __truncated__ NA NA NA ...
..$ : chr [1:17] "Leaders" NA NA NA ...
..$ : chr [1:17] "Senate\nPresident\nlist\nPresident pro tempore\nlist\nLeaders\nDemocratic Caucus\nChair\nSecretary\nPolicy Comm"| __truncated__ NA NA NA ...
..$ : chr [1:17] "Senate" NA NA NA ...
..$ : chr [1:17] "President\nlist\nPresident pro tempore\nlist\nLeaders\nDemocratic Caucus\nChair\nSecretary\nPolicy Committee Ch"| __truncated__ NA NA NA ...
..$ : chr [1:17] "House" NA NA NA ...
..$ : chr [1:17] "Speaker\nlist\nLeaders\nBipartisan Legal Advisory Group\nDemocratic Caucus\nRepublican Conference" NA NA NA ...
..$ : chr [1:17] "Districts" NA NA NA ...
..$ : chr [1:17] "List\nApportionment\nGerrymandering" NA NA NA ...
..$ : chr [1:17] "Groups" NA NA NA ...
..$ : chr [1:17] "Congressional caucus\nCaucuses of the United States CongressEthnic and racial\nAfrican-American members\nSenate"| __truncated__ NA NA NA ...
..$ : chr [1:17] "Congressional caucus" NA NA NA ...
..$ : chr [1:17] "Caucuses of the United States Congress" NA NA NA ...
..$ : chr [1:17] "Ethnic and racial" NA NA NA ...
..$ : chr [1:17] "African-American members\nSenate\nHouse\nBlack Caucus\nArab and Middle Eastern members\nAsian Pacific American "| __truncated__ NA NA NA ...
..$ : chr [1:17] "Gender and sexual identity" NA NA NA ...
..$ : chr [1:17] "LGBT members\nEquality Caucus\nWomen\nSenate\nHouse\nIssues Caucus\ncurrent House" NA NA NA ...
..$ : chr [1:17] "Occupation" NA NA NA ...
..$ : chr [1:17] "Physicians" NA NA NA ...
..$ : chr [1:17] "Religion" NA NA NA ...
..$ : chr [1:17] "Buddhist members\nHindu members\nJewish members\nMormon (LDS) members\nMuslim members\nQuaker members\nSikh members" NA NA NA ...
..$ : chr [1:17] "Related" NA NA NA ...
..$ : chr [1:17] "By length of service historically\nCurrent members by wealth\nFrom multiple states\nDied in office\n1790–1899\n"| __truncated__ NA NA NA ...
$ : tibble [16 × 12] (S3: tbl_df/tbl/data.frame)
..$ X1 : chr [1:16] "Membership" "Members" "Senate" "House" ...
..$ X2 : chr [1:16] "Members\nBy length of service\nBy shortness of service\nYoungest members\nNon-voting members\nUnseated membersS"| __truncated__ "By length of service\nBy shortness of service\nYoungest members\nNon-voting members\nUnseated members" "Members\nseniority\nDean\nFormer\nExpelled or censured\nClasses\nBorn outside the U.S.\nResigned\nAppointed\nSwitched parties" "Members\nseniority\nDean\nFormer\nExpelled, censured, and reprimanded\nServed a single term\nLost re-election i"| __truncated__ ...
..$ X3 : chr [1:16] "Members" NA NA NA ...
..$ X4 : chr [1:16] "By length of service\nBy shortness of service\nYoungest members\nNon-voting members\nUnseated members" NA NA NA ...
..$ X5 : chr [1:16] "Senate" NA NA NA ...
..$ X6 : chr [1:16] "Members\nseniority\nDean\nFormer\nExpelled or censured\nClasses\nBorn outside the U.S.\nResigned\nAppointed\nSwitched parties" NA NA NA ...
..$ X7 : chr [1:16] "House" NA NA NA ...
..$ X8 : chr [1:16] "Members\nseniority\nDean\nFormer\nExpelled, censured, and reprimanded\nServed a single term\nLost re-election i"| __truncated__ NA NA NA ...
..$ X9 : chr [1:16] "New members" NA NA NA ...
..$ X10: chr [1:16] "90th (1967)\n91st (1969)\n92nd (1971)\n93rd (1973)\n94th (1975)\n95th (1977)\n96th (1979)\n97th (1981)\n98th (1"| __truncated__ NA NA NA ...
..$ X11: chr [1:16] NA NA NA NA ...
..$ X12: chr [1:16] NA NA NA NA ...
$ : tibble [4 × 2] (S3: tbl_df/tbl/data.frame)
..$ X1: chr [1:4] "Members" "Senate" "House" "New members"
..$ X2: chr [1:4] "By length of service\nBy shortness of service\nYoungest members\nNon-voting members\nUnseated members" "Members\nseniority\nDean\nFormer\nExpelled or censured\nClasses\nBorn outside the U.S.\nResigned\nAppointed\nSwitched parties" "Members\nseniority\nDean\nFormer\nExpelled, censured, and reprimanded\nServed a single term\nLost re-election i"| __truncated__ "90th (1967)\n91st (1969)\n92nd (1971)\n93rd (1973)\n94th (1975)\n95th (1977)\n96th (1979)\n97th (1981)\n98th (1"| __truncated__
$ : tibble [2 × 2] (S3: tbl_df/tbl/data.frame)
..$ X1: chr [1:2] "Senate" "House"
..$ X2: chr [1:2] "President\nlist\nPresident pro tempore\nlist\nLeaders\nDemocratic Caucus\nChair\nSecretary\nPolicy Committee Ch"| __truncated__ "Speaker\nlist\nLeaders\nBipartisan Legal Advisory Group\nDemocratic Caucus\nRepublican Conference"
$ : tibble [5 × 2] (S3: tbl_df/tbl/data.frame)
..$ X1: chr [1:5] "Congressional caucus" "Ethnic and racial" "Gender and sexual identity" "Occupation" ...
..$ X2: chr [1:5] "Caucuses of the United States Congress" "African-American members\nSenate\nHouse\nBlack Caucus\nArab and Middle Eastern members\nAsian Pacific American "| __truncated__ "LGBT members\nEquality Caucus\nWomen\nSenate\nHouse\nIssues Caucus\ncurrent House" "Physicians" ...
$ : tibble [10 × 20] (S3: tbl_df/tbl/data.frame)
..$ Powers, privileges, procedure, committees, history, media: chr [1:10] "Powers\nArticle I\nCopyright\nCommerce (Dormant)\nContempt of Congress\nDeclaration of war\nImpeachment\nInquir"| __truncated__ "Powers" "Privileges" "Procedure" ...
..$ Powers, privileges, procedure, committees, history, media: chr [1:10] "Powers\nArticle I\nCopyright\nCommerce (Dormant)\nContempt of Congress\nDeclaration of war\nImpeachment\nInquir"| __truncated__ "Article I\nCopyright\nCommerce (Dormant)\nContempt of Congress\nDeclaration of war\nImpeachment\nInquiries\nTri"| __truncated__ "Salaries\nFranking\nImmunity" "Act of Congress\nlist\nAppropriation bill\nBill\nBudget process\nCensure\nClosed sessions\nHouse\nSenate\nClotu"| __truncated__ ...
..$ : chr [1:10] "Powers" NA NA NA ...
..$ : chr [1:10] "Article I\nCopyright\nCommerce (Dormant)\nContempt of Congress\nDeclaration of war\nImpeachment\nInquiries\nTri"| __truncated__ NA NA NA ...
..$ : chr [1:10] "Privileges" NA NA NA ...
..$ : chr [1:10] "Salaries\nFranking\nImmunity" NA NA NA ...
..$ : chr [1:10] "Procedure" NA NA NA ...
..$ : chr [1:10] "Act of Congress\nlist\nAppropriation bill\nBill\nBudget process\nCensure\nClosed sessions\nHouse\nSenate\nClotu"| __truncated__ NA NA NA ...
..$ : chr [1:10] "Senate-specific" NA NA NA ...
..$ : chr [1:10] "Advice and consent\nBlue slip (U.S. Senate)\nClasses\nExecutive communication\nExecutive session\nFilibuster\nJ"| __truncated__ NA NA NA ...
..$ : chr [1:10] "Committees" NA NA NA ...
..$ : chr [1:10] "Chairman and ranking member\nOf the Whole\nConference\nDischarge petition\nHearings\nMarkup\nOversight\nList (J"| __truncated__ NA NA NA ...
..$ : chr [1:10] "Items" NA NA NA ...
..$ : chr [1:10] "Gavels\nMace of the House\nSeal of the Senate" NA NA NA ...
..$ : chr [1:10] "History" NA NA NA ...
..$ : chr [1:10] "House history\nmemoirs\nspeaker elections\nSenate history\nelection disputes\nmemoirs\nContinental Congress\nFe"| __truncated__ NA NA NA ...
..$ : chr [1:10] "House history\nmemoirs\nspeaker elections\nSenate history\nelection disputes\nmemoirs\nContinental Congress\nFe"| __truncated__ NA NA NA ...
..$ : chr [1:10] "House history\nmemoirs\nspeaker elections\nSenate history\nelection disputes\nmemoirs\nContinental Congress\nFe"| __truncated__ NA NA NA ...
..$ : chr [1:10] "Media" NA NA NA ...
..$ : chr [1:10] "C-SPAN\nCongressional Quarterly\nThe Hill\nPolitico\nRoll Call" NA NA NA ...
$ : tibble [9 × 4] (S3: tbl_df/tbl/data.frame)
..$ X1: chr [1:9] "Powers" "Privileges" "Procedure" "Senate-specific" ...
..$ X2: chr [1:9] "Article I\nCopyright\nCommerce (Dormant)\nContempt of Congress\nDeclaration of war\nImpeachment\nInquiries\nTri"| __truncated__ "Salaries\nFranking\nImmunity" "Act of Congress\nlist\nAppropriation bill\nBill\nBudget process\nCensure\nClosed sessions\nHouse\nSenate\nClotu"| __truncated__ "Advice and consent\nBlue slip (U.S. Senate)\nClasses\nExecutive communication\nExecutive session\nFilibuster\nJ"| __truncated__ ...
..$ X3: chr [1:9] NA NA NA NA ...
..$ X4: chr [1:9] NA NA NA NA ...
$ : tibble [1 × 2] (S3: tbl_df/tbl/data.frame)
..$ X1: chr "House history\nmemoirs\nspeaker elections\nSenate history\nelection disputes\nmemoirs\nContinental Congress\nFe"| __truncated__
..$ X2: chr "House history\nmemoirs\nspeaker elections\nSenate history\nelection disputes\nmemoirs\nContinental Congress\nFe"| __truncated__
$ : tibble [16 × 32] (S3: tbl_df/tbl/data.frame)
..$ Capitol Complex (Capitol Hill): chr [1:16] "Legislativeoffices\nCongressional staff\nGov. Accountability Office (GAO)\nComptroller General\nArchitect of th"| __truncated__ "Legislativeoffices" "Offices" "Senate" ...
..$ Capitol Complex (Capitol Hill): chr [1:16] "Legislativeoffices\nCongressional staff\nGov. Accountability Office (GAO)\nComptroller General\nArchitect of th"| __truncated__ "Congressional staff\nGov. Accountability Office (GAO)\nComptroller General\nArchitect of the Capitol\nCap. Poli"| __truncated__ "Senate\nCurator\nHistorical\nLibraryHouse\nCongr. Ethics\nEmergency Planning, Preparedness, and Operations\nInt"| __truncated__ "Curator\nHistorical\nLibrary" ...
..$ : chr [1:16] "Legislativeoffices" NA "Senate" NA ...
..$ : chr [1:16] "Congressional staff\nGov. Accountability Office (GAO)\nComptroller General\nArchitect of the Capitol\nCap. Poli"| __truncated__ NA "Curator\nHistorical\nLibrary" NA ...
..$ : chr [1:16] "Offices" NA "House" NA ...
..$ : chr [1:16] "Senate\nCurator\nHistorical\nLibraryHouse\nCongr. Ethics\nEmergency Planning, Preparedness, and Operations\nInt"| __truncated__ NA "Congr. Ethics\nEmergency Planning, Preparedness, and Operations\nInterparliamentary Affairs\nLaw Revision Couns"| __truncated__ NA ...
..$ : chr [1:16] "Senate" NA NA NA ...
..$ : chr [1:16] "Curator\nHistorical\nLibrary" NA NA NA ...
..$ : chr [1:16] "House" NA NA NA ...
..$ : chr [1:16] "Congr. Ethics\nEmergency Planning, Preparedness, and Operations\nInterparliamentary Affairs\nLaw Revision Couns"| __truncated__ NA NA NA ...
..$ : chr [1:16] "Employees" NA NA NA ...
..$ : chr [1:16] "Senate\nSecretary\nChaplain\nCurator\nHistorian\nLibrarian\nPages\nParliamentarian\nSergeant at Arms and Doorke"| __truncated__ NA NA NA ...
..$ : chr [1:16] "Senate" NA NA NA ...
..$ : chr [1:16] "Secretary\nChaplain\nCurator\nHistorian\nLibrarian\nPages\nParliamentarian\nSergeant at Arms and Doorkeeper" NA NA NA ...
..$ : chr [1:16] "House" NA NA NA ...
..$ : chr [1:16] "Chaplain\nChief Administrative Officer\nClerk\nDoorkeeper\nFloor Operations\nFloor Services Chief\nHistorian\nP"| __truncated__ NA NA NA ...
..$ : chr [1:16] "Library ofCongress" NA NA NA ...
..$ : chr [1:16] "Congressional Research Service\nreports\nCopyright Office\nRegister of Copyrights\nLaw Library\nPoet Laureate\n"| __truncated__ NA NA NA ...
..$ : chr [1:16] "Gov.Publishing Office" NA NA NA ...
..$ : chr [1:16] "Public Printer\nCongressional Pictorial Directory\nCongressional Record\nOfficial Congressional Directory\nU.S."| __truncated__ NA NA NA ...
..$ : chr [1:16] "Capitol Building" NA NA NA ...
..$ : chr [1:16] "List of artwork at the United States Capitol complex\nList of portraits in the United States House of Represent"| __truncated__ NA NA NA ...
..$ : chr [1:16] "Officebuildings" NA NA NA ...
..$ : chr [1:16] "Senate\nDirksen\nHart\nMountains and Clouds\nRussellHouse\nBuilding Commission\noffice lottery\nCannon\nFord\nL"| __truncated__ NA NA NA ...
..$ : chr [1:16] "Senate" NA NA NA ...
..$ : chr [1:16] "Dirksen\nHart\nMountains and Clouds\nRussell" NA NA NA ...
..$ : chr [1:16] "House" NA NA NA ...
..$ : chr [1:16] "Building Commission\noffice lottery\nCannon\nFord\nLongworth\nO'Neill\nRayburn" NA NA NA ...
..$ : chr [1:16] "Otherfacilities" NA NA NA ...
..$ : chr [1:16] "Botanic Garden\nHealth and Fitness Facility\nHouse Recording Studio\nSenate chamber\nOld Senate Chamber\nOld Su"| __truncated__ NA NA NA ...
..$ : chr [1:16] "Related" NA NA NA ...
..$ : chr [1:16] "Capitol Hill\nUnited States Capitol cornerstone laying" NA NA NA ...
$ : tibble [15 × 6] (S3: tbl_df/tbl/data.frame)
..$ X1: chr [1:15] "Legislativeoffices" "Offices" "Senate" "House" ...
..$ X2: chr [1:15] "Congressional staff\nGov. Accountability Office (GAO)\nComptroller General\nArchitect of the Capitol\nCap. Poli"| __truncated__ "Senate\nCurator\nHistorical\nLibraryHouse\nCongr. Ethics\nEmergency Planning, Preparedness, and Operations\nInt"| __truncated__ "Curator\nHistorical\nLibrary" "Congr. Ethics\nEmergency Planning, Preparedness, and Operations\nInterparliamentary Affairs\nLaw Revision Couns"| __truncated__ ...
..$ X3: chr [1:15] NA "Senate" NA NA ...
..$ X4: chr [1:15] NA "Curator\nHistorical\nLibrary" NA NA ...
..$ X5: chr [1:15] NA "House" NA NA ...
..$ X6: chr [1:15] NA "Congr. Ethics\nEmergency Planning, Preparedness, and Operations\nInterparliamentary Affairs\nLaw Revision Couns"| __truncated__ NA NA ...
$ : tibble [2 × 2] (S3: tbl_df/tbl/data.frame)
..$ X1: chr [1:2] "Senate" "House"
..$ X2: chr [1:2] "Curator\nHistorical\nLibrary" "Congr. Ethics\nEmergency Planning, Preparedness, and Operations\nInterparliamentary Affairs\nLaw Revision Couns"| __truncated__
$ : tibble [2 × 2] (S3: tbl_df/tbl/data.frame)
..$ X1: chr [1:2] "Senate" "House"
..$ X2: chr [1:2] "Secretary\nChaplain\nCurator\nHistorian\nLibrarian\nPages\nParliamentarian\nSergeant at Arms and Doorkeeper" "Chaplain\nChief Administrative Officer\nClerk\nDoorkeeper\nFloor Operations\nFloor Services Chief\nHistorian\nP"| __truncated__
$ : tibble [2 × 2] (S3: tbl_df/tbl/data.frame)
..$ X1: chr [1:2] "Senate" "House"
..$ X2: chr [1:2] "Dirksen\nHart\nMountains and Clouds\nRussell" "Building Commission\noffice lottery\nCannon\nFord\nLongworth\nO'Neill\nRayburn"
$ : tibble [2 × 2] (S3: tbl_df/tbl/data.frame)
..$ vteOrder of precedence in the United States*: chr [1:2] "President Joe BidenVice President Kamala Harris\nGovernor (of the state in which the event is held)\nHouse Spea"| __truncated__ "*not including acting officeholders, visiting dignitaries, auxiliary executive and military personnel and most diplomats"
..$ vteOrder of precedence in the United States*: chr [1:2] "President Joe BidenVice President Kamala Harris\nGovernor (of the state in which the event is held)\nHouse Spea"| __truncated__ "*not including acting officeholders, visiting dignitaries, auxiliary executive and military personnel and most diplomats"Here, the table I want is the sixth one. We can grab it by either using double square brackets – [[6]] – or purrr’s pluck(6).
senators <- tables |>
pluck(6)
glimpse(senators)Rows: 100
Columns: 12
$ State <chr> "Alabama", "Alabama", "Alaska", "Alaska",…
$ Portrait <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
$ Senator <chr> "Tommy Tuberville", "Katie Britt", "Lisa …
$ Party <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
$ Party <chr> "Republican", "Republican", "Republican",…
$ Born <chr> "(1954-09-18) September 18, 1954 (age 70)…
$ `Occupation(s)` <chr> "Investment management firm partner\nColl…
$ `Previous electiveoffice(s)` <chr> "None", "None", "Alaska House of Represen…
$ Education <chr> "Southern Arkansas University (BS)", "Uni…
$ `Assumed office` <chr> "January 3, 2021", "January 3, 2023", "De…
$ Class <chr> "2026Class 2", "2028Class 3", "2028Class …
$ `Residence[6]` <chr> "Auburn[7]", "Montgomery", "Girdwood", "A…## alternative approach using css
senators <- us_senators |>
html_elements(css = "#senators") |>
html_table() |>
pluck(1) |>
janitor::clean_names()You can see that the tibble contains “dirty” names and that the party column appears twice – which will make it impossible to work with the tibble later on. Hence, I use clean_names() from the janitor package to fix that.
Extracting attributes
You can also extract attributes such as links using html_attrs(). An example would be to extract the headlines and their corresponding links from r-bloggers.com.
rbloggers <- read_html("https://www.r-bloggers.com")A quick check with the SelectorGadget told me that the element I am looking for is of class “.loop-title” and the child of it is “a”, standing for normal text. With html_attrs() I can extract the attributes. This gives me a list of named vectors containing the name of the attribute and the value:
Links are stored as attribute “href” – hyperlink reference. html_attr() allows me to extract the attribute’s value. Hence, building a tibble with the article’s title and its corresponding hyperlink is straight-forward now:
tibble(
title = r_blogger_postings |> html_text2(),
link = r_blogger_postings |> html_attr(name = "href")
)# A tibble: 20 × 2
title link
<chr> <chr>
1 Introducing Rlinguo, a native mobile app that runs R http…
2 Breaking In and Out of Looped Code: A Beginner’s Guide to C Loop Contr… http…
3 Nice meeting! http…
4 A Complete Guide to Using na.rm in R: Vector and Data Frame Examples http…
5 Introducing the rOpenSci Localization and Translation Guidelines http…
6 Latent Growth Curve Models using the Lavaan Package in R workshop http…
7 Satellite mapping of surface waters in R http…
8 Use an LLM to translate help documentation on-the-fly http…
9 How to Use na.omit in R: A Comprehensive Guide to Handling Missing Val… http…
10 Extracting Data from OECD Databases in R: Using the oecd and rsdmx Pac… http…
11 RObservations #50: a journey across the United States with {mapBliss} http…
12 Death rates by cause of death by @ellis2013nz http…
13 Understanding Storage Media in Linux: A Beginner’s Guide http…
14 Diffify & Posit Package Manager http…
15 xkcd’atorics http…
16 How to Use drop_na to Drop Rows with Missing Values in R: A Complete G… http…
17 Understanding Switch Statements in C Programming http…
18 How to Select Row with Max Value in Specific Column in R: A Complete G… http…
19 Analyzing Driver License Suspensions with R http…
20 Parallel and Asynchronous Programming in Shiny with future, promise, f… http…Another approach for this would be using the polite package and its function html_attrs_dfr() which binds together all the different attributes column-wise and the different elements row-wise.
rbloggers |>
html_elements(css = ".loop-title a") |>
html_attrs_dfr() |>
select(title = 3,
link = 1) |>
glimpse()Rows: 20
Columns: 2
$ title <chr> "Introducing Rlinguo, a native mobile app that runs R", "Breakin…
$ link <chr> "https://www.r-bloggers.com/2024/12/introducing-rlinguo-a-native…Exercise
- Download the links and names of the top 250 IMDb movies. Put them in a tibble with the columns
rank– in numeric format (you know regexes already),title,urlto IMDb entry,rating– in numeric format,number_votes– the number of votes a movie has received, in numeric format. Also, what do you notice?
Solution. Click to expand!
imdb_top250 <- read_html("https://www.imdb.com/chart/top/?ref_=nv_mv_250")
movies <- tibble(
rank = imdb_top250 |>
html_elements(".cli-title .ipc-title__text") |>
html_text2() |>
str_extract("^[0-9]+(?=\\.)") |>
parse_integer(),
title = imdb_top250 |>
html_elements(".cli-title .ipc-title__text") |>
html_text2() |>
str_remove("^[0-9]+\\. "),
url = imdb_top250 |>
html_elements(".cli-title a") |>
html_attr("href") |>
str_c("https://www.imdb.com", x = _),
rating = imdb_top250 |>
html_elements(".ratingGroup--imdb-rating") |>
html_text() |>
str_extract("[0-9]\\.[0-9]") |>
parse_double(),
no_votes = imdb_top250 |>
html_elements(".ratingGroup--imdb-rating") |>
html_text() |>
str_remove("^[0-9]\\.[0-9]") |>
str_remove_all("[() ]")
)Automating scraping
Well, grabbing singular points of data from websites is nice. However, if you want to do things such as collecting large amounts of data or multiple pages, you will not be able to do this without some automation.
An example here would again be the R-bloggers page. It provides you with plenty of R-related content. If you were now eager to scrape all the articles, you would first need to acquire all the different links leading to the blog postings. Hence, you would need to navigate through the site’s pages first to acquire the links.
In general, there are two ways to go about this. The first is to manually create a list of URLs the scraper will visit and take the content you need, therefore not needing to identify where it needs to go next. The other one would be automatically acquiring its next destination from the page (i.e., identifying the “go on” button). Both strategies can also be nicely combined with some sort of session().
Looping over pages
For the first approach, we need to check the URLs first. How do they change as we navigate through the pages?
url_1 <- "https://www.r-bloggers.com/page/2/"
url_2 <- "https://www.r-bloggers.com/page/3/"
initial_dist <- adist(url_1, url_2, counts = TRUE) |>
attr("trafos") |>
diag() |>
str_locate_all("[^M]")
str_sub(url_1, start = initial_dist[[1]][1]-5, end = initial_dist[[1]][1]+5) # makes sense for longer urls[1] "page/2/"str_sub(url_2, start = initial_dist[[1]][1]-5, end = initial_dist[[1]][1]+5)[1] "page/3/"There is some sort of underlying pattern and we can harness that. url_1 refers to the second page, url_2 to the third. Hence, if we just combine the basic URL and, say, the numbers from 1 to 10, we could then visit all the pages (exercise 3a) and extract the content we want.
urls <- str_c("https://www.r-bloggers.com/page/", 1:10, "/") # this is the stringr equivalent of paste()
urls [1] "https://www.r-bloggers.com/page/1/" "https://www.r-bloggers.com/page/2/"
[3] "https://www.r-bloggers.com/page/3/" "https://www.r-bloggers.com/page/4/"
[5] "https://www.r-bloggers.com/page/5/" "https://www.r-bloggers.com/page/6/"
[7] "https://www.r-bloggers.com/page/7/" "https://www.r-bloggers.com/page/8/"
[9] "https://www.r-bloggers.com/page/9/" "https://www.r-bloggers.com/page/10/"You can run this in a for-loop, here’s a quick revision. For the loop to run efficiently, space for every object should be pre-allocated (i.e., you create a list beforehand, and its length can be determined by an educated guess).
## THIS IS PSEUDO CODE!!!
result_list <- vector(mode = "list", length = length(urls)) # pre-allocate space!!!
starting_link <- "https://www.r-bloggers.com/page/1/"
####PSEUDO CODE!!!
for (i in seq_along(urls)){
read in urls[[i]] --> page <- read_html(url)
store content of page in result_list result_list[[i]] <- extract_content(page)
}Exercise
- Scrape 5 pages of the latest UN press releases in an automated fashion. Make sure to take breaks between requests by including
Sys.sleep(2). For each iteration, store the articles and links in a tibble containing the columnstitle,link, anddate(bonus: store it in date format). (Tip: wrap the code that extracts and stores content in a tibble in a function.)
- Do so using running numbers in the urls.
- Do so by using
session()in a loop. (Note: make sure to specifycss =)
Solution. Click to expand!
extract_press_releases <- function(page){
tibble(
title = page |>
html_elements(".field__item a") |>
html_text2(),
link = page |>
html_elements(".field__item a") |>
html_attr("href"),
date = page |>
html_elements(".field--type-datetime") |>
html_text2() |>
as.Date(format = "%d %B %Y")
)
}
#a
urls <- str_c("https://press.un.org/en/content/secretary-general/press-release?page=", 0:4)
pages <- map(urls,
\(x){
Sys.sleep(2)
read_html(x) |>
extract_press_releases()
}
)
#b
un_session <- session("https://press.un.org/en/content/secretary-general/press-release")
i <- 1
page_list <- vector(mode = "list", length = 5L)
while (i < 6) {
page_list[[i]] <- read_html(un_session) |>
extract_press_releases()
un_session <- un_session |>
session_follow_link(css = ".me-s .page-link")
i <- i + 1
Sys.sleep(2)
}Conclusion
To sum it up: when you have a good research idea that relies on Digital Trace Data that you need to collect, ask yourself the following questions:
- Is there an R package for the web service?
- If 1. == FALSE: Is there an API where I can get the data (if TRUE, use it) – next chapter.
- If 1. == FALSE & 2. == FALSE: Is screen scraping an option and any structure in the data that you can harness?
If you have to rely on screen scraping, also ask yourself the question how you can minimize the number of requests you make to the server. Going back and forth on web pages or navigating through them might not be the best option since it requires multiple requests. The most efficient way is usually to try to get a list of URLs of some sort which you can then just loop over.