needs(tidyverse, furrr)
#' Create initial grid for Schelling model
#'
#' @param dimensions Size of square grid
#' @param share_empty Proportion of empty cells
#' @param share_type1 Proportion of type 1 agents
#' @param share_type2 Proportion of type 2 agents
#' @return Matrix representing initial grid state
create_grid <- function(dimensions = 25,
share_empty = 0.2,
share_type1 = 0.4,
share_type2 = 0.4) {
if(abs(share_empty + share_type1 + share_type2 - 1) > 0.001) {
stop("Proportions must sum to 1")
}
# Create grid with proper proportions
total_cells <- dimensions * dimensions
grid_values <- c(
rep(0, floor(total_cells * share_empty)), # Empty cells
rep(1, floor(total_cells * share_type1)), # Type 1
rep(2, floor(total_cells * share_type2)) # Type 2
)
# Fill any remaining cells due to rounding
if(length(grid_values) < total_cells) {
grid_values <- c(grid_values,
rep(0, total_cells - length(grid_values)))
}
# Randomly arrange and convert to matrix
matrix(
sample(grid_values),
nrow = dimensions,
ncol = dimensions
)
}
initial_grid <- create_grid()Chapter 18: Agent-based Modeling
Schelling model
Let’s build a Schelling model together. The inspiration for parts of the code come from this blog post – I tried to write the code in a cleaner fashion though.
The steps we will program today are the follwoing:
- Initialization:
- Create field with n x n dimensions
- Create agents with certain attributes and put them on the field
- Determine happiness criterion
- Simulation
- Determine each agent’s happiness level
- Move unhappy agents to empty field
- Repeat until time is up or all agents are happy
Initialization
The create_grid function is responsible for creating the initial state of the Schelling model’s world. It constructs a square grid populated with agents of two different types and empty spaces, with careful attention to maintaining specified proportions. Here’s how it works:
Parameter Validation:
- First checks if the three share parameters (empty, type1, type2) sum to 1
- Uses a small tolerance (0.001) to account for floating-point arithmetic
- Throws an error if proportions are invalid
Grid Population Calculation:
- Calculates total number of cells as dimensions squared
- Uses
floor()when computing cell counts to handle non-integer results - Creates three groups of values:
- 0s representing empty cells
- 1s representing type 1 agents
- 2s representing type 2 agents
Handling Rounding Issues:
Due to floor() operations, there might be a few unallocated cells. These remaining cells are filled with empty spaces (0s). This ensures the grid is completely filled while maintaining close to desired proportions
Grid Construction:
Uses sample() to randomly shuffle all cell values, then converts the shuffled vector into a matrix with specified dimensions. Finally, it returns a square matrix representing the initial grid state.
The default parameters (25x25 grid, 20% empty, 40% each type) are chosen to demonstrate typical segregation patterns while maintaining reasonable computational efficiency. The equal proportions of agent types (40% each) allow for clear observation of emerging segregation patterns.
running initial_grid <- create_grid() creates a 25x25 matrix where: * Approximately 125 cells (20%) are empty (0s) * Approximately 250 cells (40%) contain type 1 agents (1s) * Approximately 250 cells (40%) contain type 2 agents (2s) * Also, all values are randomly distributed throughout the grid
Note: since we will create individual functions, we prepare descriptions for each function’s parameters using the roxygen2 documentation style. Find more information here. This would also be the way to document different functions in a package (which is basically a collection of functions).
The first step is determining each agent’s happiness:. For this, we first use the get_neighbors function that identifies all valid neighboring cells for a given position in the grid. It uses the Moore neighborhood definition, meaning it considers all 8 surrounding cells (horizontally, vertically, and diagonally adjacent). The function works in several steps:
- First, it determines the grid dimensions from the input grid
- Using expand_grid, it creates all possible combinations of offsets (-1, 0, 1) for both rows and columns
- It filters out the center cell (0,0 offset) since a cell isn’t its own neighbor
- It calculates actual neighbor coordinates by adding the offsets to the input position
- It filters out any invalid coordinates that would fall outside the grid boundaries
- Finally, it extracts and returns the values from these valid neighbor positions
#' Get neighbors for a given cell
#'
#' @param grid Current grid state
#' @param row Row index
#' @param col Column index
#' @return Vector of neighbor values
get_neighbors <- function(grid, row, col) {
dimensions <- nrow(grid)
# Generate all possible neighbor coordinates
neighbor_coords <- expand_grid(
row_offset = -1:1,
col_offset = -1:1
) %>%
filter(!(row_offset == 0 & col_offset == 0)) %>% # Remove center cell
mutate(
neighbor_row = row + row_offset,
neighbor_col = col + col_offset
) %>%
filter(
neighbor_row >= 1,
neighbor_row <= dimensions,
neighbor_col >= 1,
neighbor_col <= dimensions
)
# Extract neighbor values
map2_dbl(
neighbor_coords$neighbor_row,
neighbor_coords$neighbor_col,
~grid[.x, .y]
)
}Once we have extracted the neighborhood, we can check whether the neighbors are happy. This is the case if the share of same type neighboring cells (empty ones do not count) are of the same type as the cell. Here, we use 0.4 as the satisfaction threshold; higher thresholds lead to stronger segregation.
- It first gets the agent’s type (0 for empty, 1 or 2 for different agent types)
- Empty cells are automatically considered satisfied (they can’t be dissatisfied)
- It gets all neighbors using the previously defined get_neighbors function
- If an agent has no neighbors at all, they’re considered satisfied by default
- It filters out empty cells from the neighbor list since they don’t count toward similarity
- If all neighbors are empty cells, the agent is satisfied
- It calculates the ratio of similar neighbors (same type) to total non-empty neighbors
- Finally, it compares this ratio to the threshold parameter
#' Check if agent is satisfied with their neighborhood
#'
#' @param grid Current grid state
#' @param row Row index
#' @param col Column index
#' @param threshold Minimum proportion of similar neighbors for satisfaction
#' @return Boolean indicating if agent is satisfied
is_satisfied <- function(grid, row, col, threshold = 0.4) {
agent_type <- grid[row, col]
# Empty cells are always satisfied
if(agent_type == 0) return(TRUE)
neighbors <- get_neighbors(grid, row, col)
# If no neighbors, agent is satisfied
if(length(neighbors) == 0) return(TRUE)
# Count similar non-empty neighbors
non_empty_neighbors <- neighbors[neighbors != 0]
if(length(non_empty_neighbors) == 0) return(TRUE)
similar_neighbors <- sum(non_empty_neighbors == agent_type)
similarity_ratio <- similar_neighbors / length(non_empty_neighbors)
similarity_ratio >= threshold
}Unhappy cells move to empty cells. For this, the find_empty_cells function identifies all unoccupied positions in the grid to determine “free spots.” The function:
- Uses which with arr.ind = TRUE to find the row and column indices of all cells containing 0 (empty)
- Converts the result to a tibble for easier manipulation with tidyverse functions
- Renames the columns to ‘row’ and ‘col’ for clarity
This function is used when an unsatisfied agent needs to move, providing the set of all possible destinations. The use of tibble format makes it easy to randomly sample from these positions when selecting a new location for a moving agent.
#' Find all empty cells in grid
#'
#' @param grid Current grid state
#' @return Tibble of empty cell coordinates
find_empty_cells <- function(grid) {
which(grid == 0, arr.ind = TRUE) %>%
as_tibble() %>%
rename(row = row, col = col)
}Now we can wrap this all in a function that finally moves the agents to an empty cell. The step_simulation function executes one complete time step of the Schelling model simulation. During each step:
- It iterates through every cell in the grid systematically
- For each non-empty cell, it checks if the agent is satisfied using is_satisfied
If an agent is dissatisfied:
- It finds all empty cells using
find_empty_cells - If empty cells exist, it randomly selects one as the new location
- Moves the agent to the new location by updating grid values
- Increments the move counter
Finally, it returns both the updated grid and the number of moves made.
The number of moves is crucial as it serves as a convergence metric – when no moves are made in a step, the simulation has reached a stable state. The function uses a nested loop structure for grid traversal, though future optimizations could potentially vectorize this operation.
#' Perform one step of the simulation
#'
#' @param grid Current grid state
#' @param threshold Satisfaction threshold
#' @return List containing updated grid and number of moves made
step_simulation <- function(grid, threshold = 0.4) {
dimensions <- nrow(grid)
moves <- 0
# Check each cell
for(row in 1:dimensions) {
for(col in 1:dimensions) {
# Skip empty cells
if(grid[row, col] == 0) next
# Check if agent is satisfied
if(!is_satisfied(grid, row, col, threshold)) {
# Find empty cells
empty_cells <- find_empty_cells(grid)
if(nrow(empty_cells) > 0) {
# Choose random empty cell
new_location <- empty_cells %>%
slice_sample(n = 1)
# Move agent
grid[new_location$row, new_location$col] <- grid[row, col]
grid[row, col] <- 0
moves <- moves + 1
}
}
}
}
list(grid = grid, moves = moves)
}Finally, the run_schelling function orchestrates the entire simulation process. It manages both the execution and visualization of the Schelling model. It handles:
- Initialization:
- Creates initial grid with specified proportions of agent types
- Optionally displays the initial state using the image function
- Prepares storage for recording simulation history
- Simulation Loop:
- Repeatedly calls step_simulation until either:
- No moves occur (stable state reached)
- or maximum steps limit is reached
- Records grid state and move count at each step
- Visualization:
- If plotting is enabled, shows initial and final states
- Uses white for empty cells, blue for type 1 agents, red for type 2 agents
- Includes step count in final plot title
- Results Collection: returns a comprehensive list containing:
- Final grid configuration
- Total number of steps taken
- Complete history of all states and moves
The function parameters allow the fine-tuning of the simulation, including grid size, population ratios, satisfaction threshold, and maximum steps. Hence, the function is highly flexible for exploring different scenarios and testing hypotheses about segregation patterns.
#' Run complete simulation
#'
#' @param dimensions Grid size
#' @param share_empty Proportion of empty cells
#' @param share_type1 Proportion of type 1 agents
#' @param share_type2 Proportion of type 2 agents
#' @param threshold Satisfaction threshold
#' @param max_steps Maximum number of steps
#' @param plot Whether to create plots
#' @return List containing simulation results
run_schelling <- function(dimensions = 25,
share_empty = 0.2,
share_type1 = 0.4,
share_type2 = 0.4,
threshold = 0.4,
max_steps = 100,
plot = TRUE) {
# Initialize
grid <- create_grid(dimensions, share_empty, share_type1, share_type2)
if(plot) {
cat("Initial state:\n")
image(
grid,
col = c("white", "blue", "red"),
main = "Initial Grid State",
xlab = "",
ylab = ""
)
}
# Storage for results
results <- vector("list", max_steps)
# Run simulation
step <- 1
repeat {
step_result <- step_simulation(grid, threshold)
grid <- step_result$grid
results[[step]] <- list(
grid = grid,
moves = step_result$moves
)
# Check stopping conditions
if(step_result$moves == 0 || step == max_steps) break
step <- step + 1
}
if(plot) {
cat(sprintf("\nFinal state after %d steps:\n", step))
image(
grid,
col = c("white", "blue", "red"),
main = sprintf("Final Grid State (Step %d)", step),
xlab = "",
ylab = ""
)
}
# Return results
list(
final_grid = grid,
steps = step,
history = results[1:step]
)
}
#run_schelling(dimensions = 25,
# share_empty = 0.2,
# share_type1 = 0.4,
# share_type2 = 0.4,
# threshold = 0.8,
# max_steps = 100,
# plot = TRUE)In practice, you might want to use a vectorized version, which is a bit opaquely coded. Find the code here:
#' Create initial grid for Schelling model
#' @description Creates initial grid with vectorized operations
create_grid <- function(dimensions = 25,
share_empty = 0.2,
share_type1 = 0.4,
share_type2 = 0.4) {
if(abs(share_empty + share_type1 + share_type2 - 1) > 0.001) {
stop("Proportions must sum to 1")
}
total_cells <- dimensions * dimensions
grid <- sample(
c(0, 1, 2),
size = total_cells,
replace = TRUE,
prob = c(share_empty, share_type1, share_type2)
)
matrix(grid, nrow = dimensions)
}
#' Get all neighbor values for entire grid at once
#' @description Vectorized neighbor computation for all cells
get_all_neighbors <- function(grid) {
dimensions <- nrow(grid)
# Create shifted versions of the grid for all 8 directions
shifts <- list(
up = rbind(grid[-1, ], NA),
down = rbind(NA, grid[-dimensions, ]),
left = cbind(grid[, -1], NA),
right = cbind(NA, grid[, -dimensions]),
up_left = rbind(cbind(grid[-1, -1], NA), NA),
up_right = rbind(cbind(NA, grid[-1, -dimensions]), NA),
down_left = rbind(NA, cbind(grid[-dimensions, -1], NA)),
down_right = rbind(NA, cbind(NA, grid[-dimensions, -dimensions]))
)
# Stack all shifts into a 3D array
neighbor_array <- array(
unlist(shifts),
dim = c(dimensions, dimensions, 8)
)
# Return array of all neighbors for each cell
neighbor_array
}
#' Calculate satisfaction for all cells simultaneously
#' @description Vectorized satisfaction calculation
calculate_satisfaction <- function(grid, neighbors_array, threshold = 0.4) {
dimensions <- nrow(grid)
# Create grid of agent types repeated for each neighbor
agent_types <- array(
rep(grid, 8),
dim = c(dimensions, dimensions, 8)
)
# Calculate similarity with each neighbor
similar_neighbors <- neighbors_array == agent_types
# Count non-empty neighbors and similar neighbors
non_empty_neighbors <- !is.na(neighbors_array) & neighbors_array != 0
total_non_empty <- apply(non_empty_neighbors, c(1,2), sum)
total_similar <- apply(similar_neighbors & non_empty_neighbors, c(1,2), sum)
# Calculate satisfaction ratio
satisfaction_ratio <- total_similar / pmax(total_non_empty, 1)
# Empty cells are always satisfied
satisfaction <- (grid == 0) | (satisfaction_ratio >= threshold)
satisfaction
}
#' Run vectorized Schelling simulation
#' @description Main simulation function using vectorized operations
run_vectorized_schelling <- function(dimensions = 25,
share_empty = 0.2,
share_type1 = 0.4,
share_type2 = 0.4,
threshold = 0.4,
max_steps = 100,
plot = TRUE) {
# Initialize
grid <- create_grid(dimensions, share_empty, share_type1, share_type2)
if(plot) {
cat("Initial state:\n")
image(
grid,
col = c("white", "blue", "red"),
main = "Initial Grid State",
xlab = "",
ylab = ""
)
}
# Storage for results
results <- vector("list", max_steps)
# Run simulation
step <- 1
repeat {
# Get all neighbors at once
neighbors_array <- get_all_neighbors(grid)
# Calculate satisfaction for all cells
satisfied <- calculate_satisfaction(grid, neighbors_array, threshold)
# Find unsatisfied agents and empty cells
unsatisfied_positions <- which(!satisfied & grid != 0, arr.ind = TRUE)
empty_positions <- which(grid == 0, arr.ind = TRUE)
# If no unsatisfied agents or no empty cells, we're done
if(nrow(unsatisfied_positions) == 0 || nrow(empty_positions) == 0) {
moves <- 0
} else {
# Randomly select which agents to move and where
n_moves <- min(nrow(unsatisfied_positions), nrow(empty_positions))
# Select random unsatisfied agents to move
move_from <- unsatisfied_positions[sample(nrow(unsatisfied_positions), n_moves), , drop = FALSE]
# Select random empty positions to move to
move_to <- empty_positions[sample(nrow(empty_positions), n_moves), , drop = FALSE]
# Perform all moves at once
for(i in seq_len(n_moves)) {
# Store agent type
agent_type <- grid[move_from[i, "row"], move_from[i, "col"]]
# Move agent
grid[move_from[i, "row"], move_from[i, "col"]] <- 0
grid[move_to[i, "row"], move_to[i, "col"]] <- agent_type
}
moves <- n_moves
}
# Store results
results[[step]] <- list(
grid = grid,
moves = moves
)
# Check stopping conditions
if(moves == 0 || step == max_steps) break
step <- step + 1
}
if(plot) {
cat(sprintf("\nFinal state after %d steps:\n", step))
image(
grid,
col = c("white", "blue", "red"),
main = sprintf("Final Grid State (Step %d)", step),
xlab = "",
ylab = ""
)
}
list(
final_grid = grid,
steps = step,
history = results[1:step]
)
}Let’s compare performance. First the non-vectorized, then the vectorized version:
# Non-vectorized
system.time({
result <- run_schelling(
dimensions = 50,
threshold = 0.6,
max_steps = 10
)
})Initial state: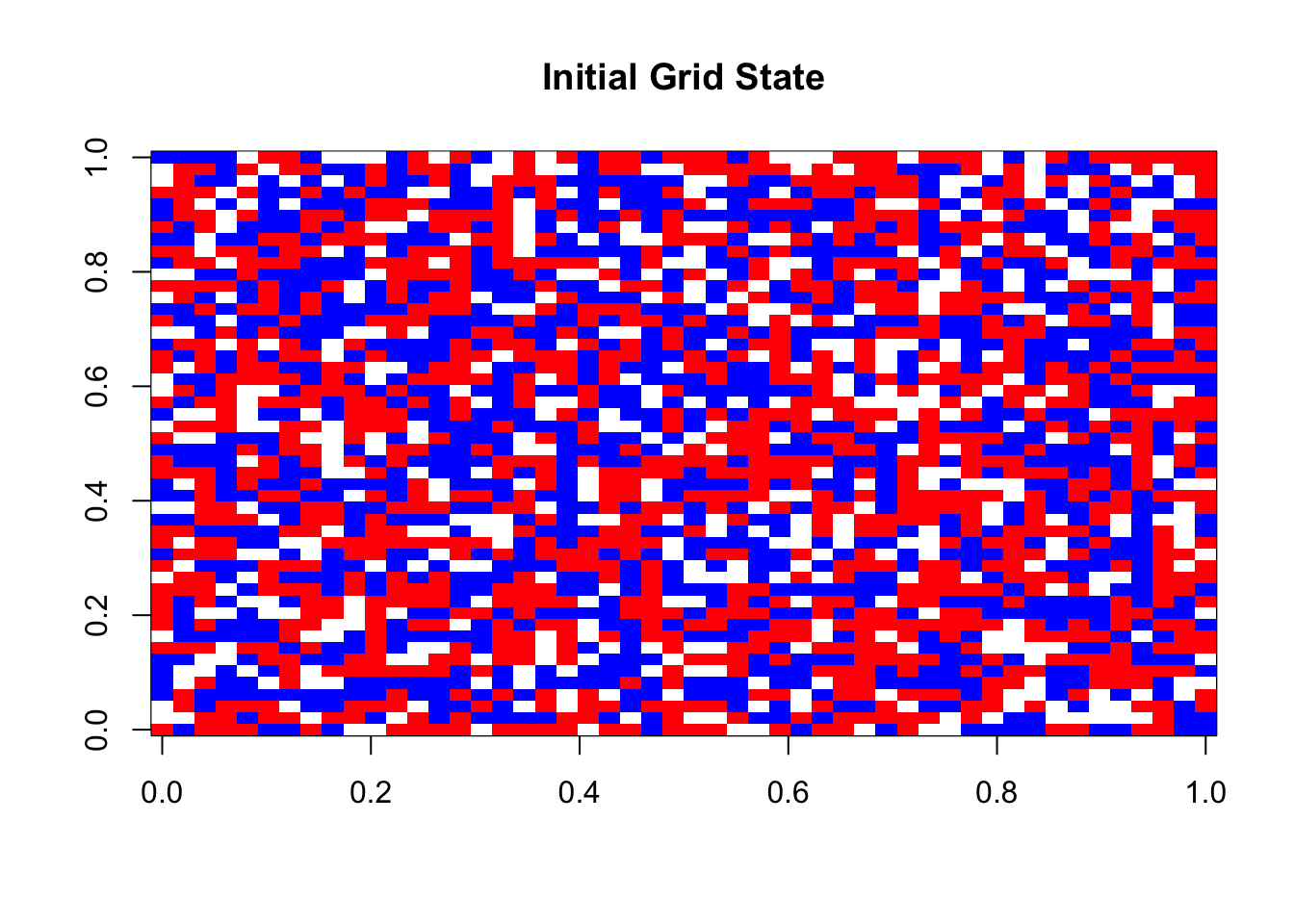
Final state after 10 steps: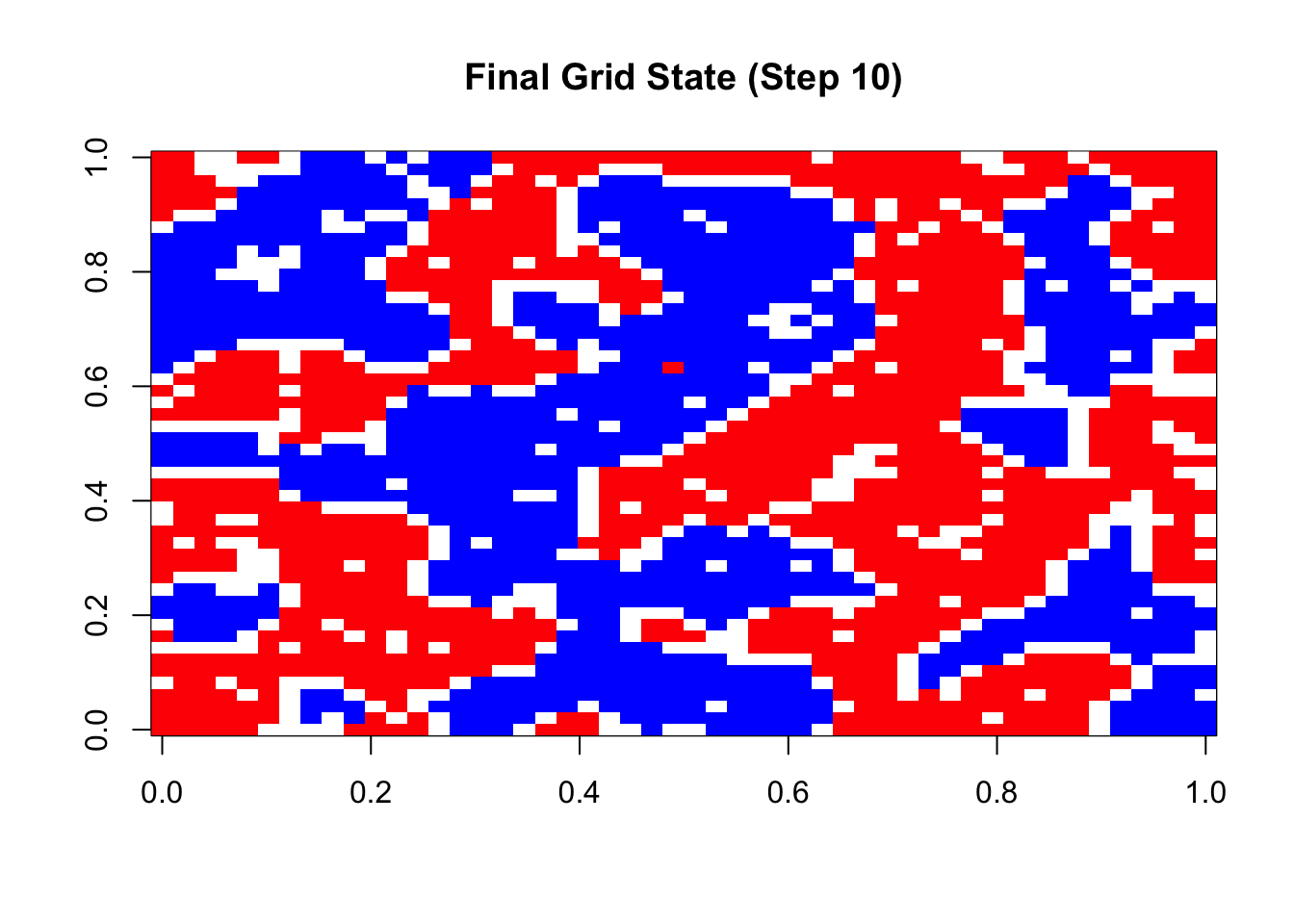
user system elapsed
30.935 0.089 31.327 # Vectorized
system.time({
result <- run_vectorized_schelling(
dimensions = 50,
threshold = 0.6,
max_steps = 10
)
})Initial state: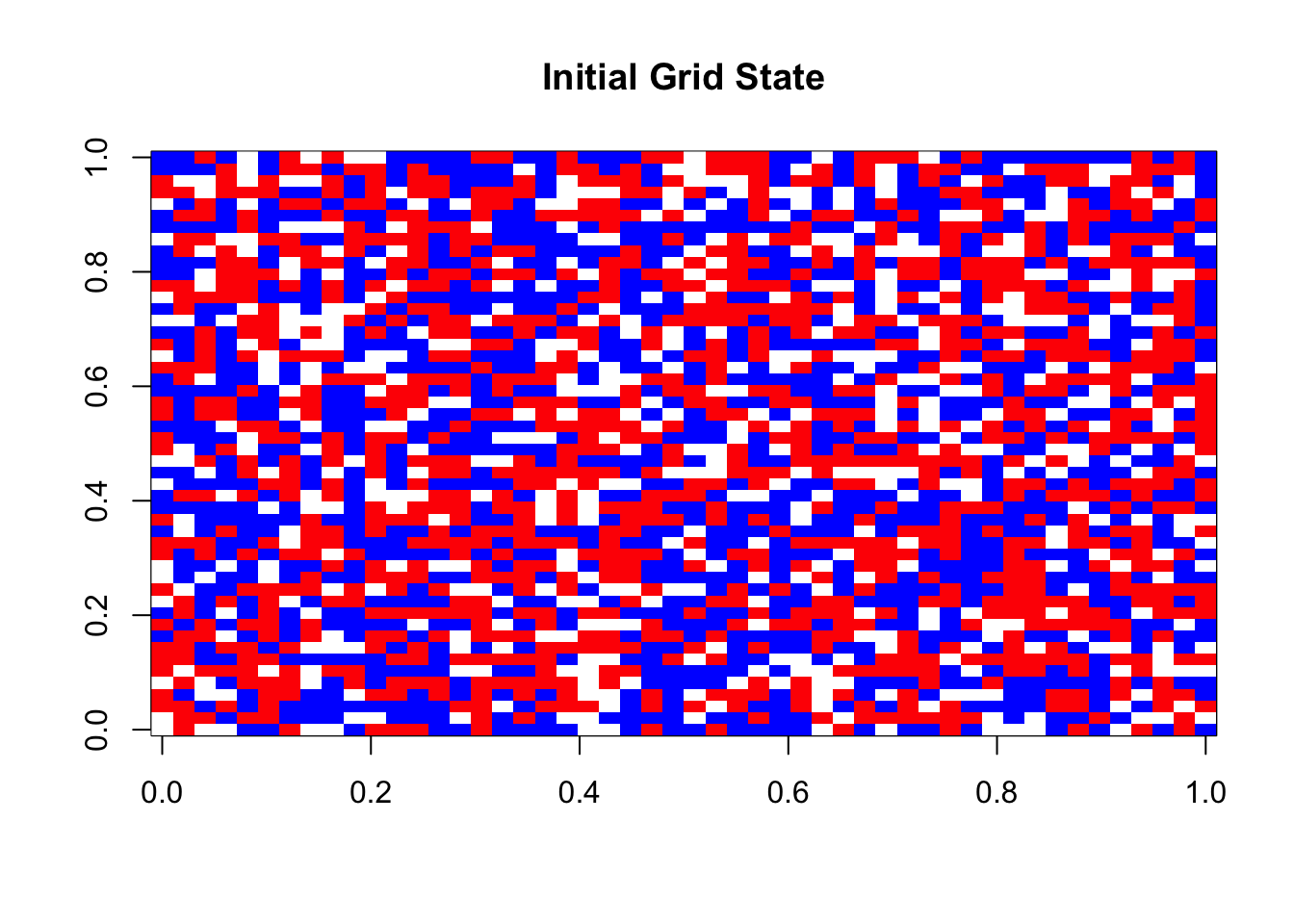
Final state after 10 steps: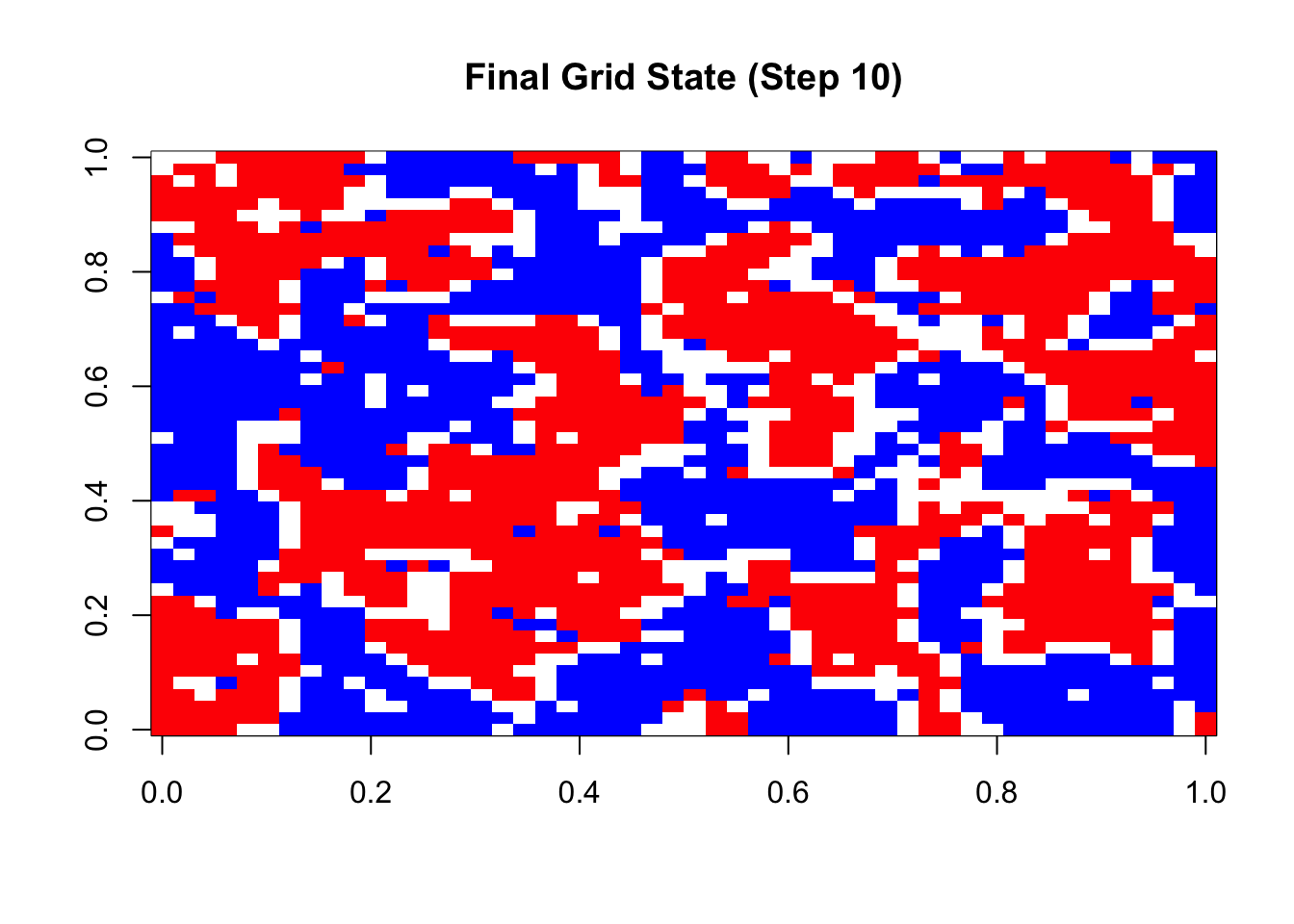
user system elapsed
0.122 0.007 0.134 44s vs. 0.2s, quite impressive. I must say that generative AI is fairly good at speeding up your code, so here it might be something you might consider.
Now that we have this sped up function, we can use different parameters, run different simulations, and you can look at the results. furrr gives us the option to use the future_map() funtion. This is basically purrr::map() running in parallel.
input_table <- expand_grid(
max_steps = 50,
dimensions = c(25, 50),
share_type1 = seq(0.2, 0.4, by = 0.1),
threshold = seq(0.2, 0.8, by = 0.2)
) %>%
mutate(share_type2 = share_type1,
share_empty = 1 - (share_type1 + share_type2)) %>%
filter(share_empty > 0.1)
plan(multisession, workers = 8)
results <- future_pmap(input_table,
run_vectorized_schelling,
.options = furrr_options(seed = 123))More complicated model: replicating Baldassarri and Bearman (2007)
In a next step, we will replicate Baldassarri and Bearman (2007). We will do this according to the ODD protocol, which is the preferred way to report these models.
###In the first step, researchers need to justify the purpose the model. This encompasses not only stating the research question, but also what general purpose the model is supposed to serve for. Those high-level purposes are not necessarily perfectly distinct and a model might serve for more than one. However, when you construct a model, you should clearly think of one purpose and garner it towards this purpose.
Some of the most important high-level purposes of ABMs are prediction (of an outcome), explanation (of phenomena through tangible causal chains consisting of mechanisms), description (of the components that matter in a particular case), theoretical exposition (hypothesis testing), illustration (of an idea or theory), analogy (to illustrate a way you could think about a phenomenon – such as opinion spreading through models from epidemiology), and social learning (modeling the evolution of people’s (shared) understandings) (illustrations and more can be found in Edmonds et al. 2019).
The “patterns” part of the first component refers to the (real-world) phenomenon you strive to explain. It can be seen as a set of criteria that helps you in assessing whether the model is realistic enough. The patterns can be derived from observations on either the micro- or macro level in the real world or inductively from the literature. For instance, the pattern we wanted to observe in the diffusion model was the S-shaped curve we know from real-world diffusion processes, or in the Schelling model clearly segregated neighborhoods.
A clearly formulated purpose and pattern part helps the reader with deciding independently whether they deem the model a success or not. Moreover, it helps the researcher to decide what is relevant for their model and what not – and, hence, what they need to include. It is advisable to clearly link the model’s outcomes/results to the question. This will also inform your decision on what to report and how. Relevant terms need to be sufficiently specified. Alternative use-cases of the model need to be included (e.g., diffusion models can be useful for modeling epidemics as well as rumors or trends). Do not get into the specifics of your model already, this will come in the later parts of the ODD protocol. And, finally, formulate patterns in such a way that they are testable: how can you reliably (statistically) determine whether they are present or not? Also, it needs to be motivated why you assume them to be of relevance for your model. This usually stems from empirical observation.
Purpose and pattern of Baldassarri and Bearman (2007):
They set out to determine the mechanisms behind two empirical paradoxes:
“The first is the simultaneous presence and absence of political polarization—the fact that attitudes rarely polarize, even though people believe polarization to be common. The second is the simultaneous presence and absence of social polarization—the fact that while individuals experience attitude homogeneity in their interpersonal networks, these networks retain attitude heterogeneity overall.” (p. 784)
Therefore, the patterns they are searching for are homogeneous individual discussion networks, whereas the social structures themselves remain heterogeneous. Moreover, they claim that there are topics (so-called “takeoff issues”) that garner the lion share of attention, leading to no polarization with regard to other topics.
Entities, state variables, and scales
The entities of the model are the objects that in their entirety comprise the model. Objects are usually of different kinds and multitude. Typically there are the following kinds of entities in there: spatial units such as grid cells or, more abstractly speaking, actors’ position in a network; the actors (agents) themselves; agent collectives/groups; the environment, such as time trackers, observers (of the distribution of agents). The inclusion of entities should be theoretically motivated and needs to be justified.
State variables are the attributes of the different entities. Those can be used to distinguish entities of the same kind (e.g., color in the Schelling model) or track changes over time (e.g., position of the agent in the Schelling model). When including state variables, one also has to descriebe them in further detail: what are they representing; are they dynamic; what’s the values they can take on and what type are they of. It usually makes sense to perform those descriptions in a table. Note the difference between state variables and parameters: state variables capture the entity’s state over time or are used to distinguish entities. Therefore, agents’ gender is a state variable, the happiness threshold in the Schelling model is a parameter. If a value is drawn from, say, a normal distribution as the opinion value in Baldassarri and Bearman (2007), the agent’s value is captured as a state variable. In this case, the parameters would be the characteristics of the normal distribution (mean and standard deviation). State variables should be as “low-level” as possible. If a value is derived from other state variables, it is no state variable in itself. Also, do not mention why those variables might change.
When thinking about which state variables to include, ask yourself: “if you want (as modelers often do) to stop the model and save it in its current state, so it can be re-started in exactly the same state, what is the minimum information you must save? Those essential characteristics of each kind of entity are its state variables.” (Grimm et al. 2020:S1: 9)
Scales are referring to the extent of the model: its spatial and temporal scale. What does one time step mean? What does one square grid cell refer to? Also, justify your decision for a certain decision. This must only be included if it applies. However, you should give an abstract discussion (e.g., in the Schelling model cells represent households and one step is one move, so roughly a couple of months). This makes the model more tangible.
Note that in this part you should not discuss the model processes and behaviors. Stick to the entities, state variables, and scales.
Entities, state variables, and scales in Baldassarri and Bearman (2007):
The entities are the 100 individual actors. Their state variables are issue interest/opinion towards issues and the (perceived) distance to other actors’ \(\lambda\). Scale-wise, the simulations will run for 500 steps and actors can communicate to a certain number of actors (up to ~12) during each time step.
#' Initialize actors for opinion dynamics model
#'
#' @description
#' Creates initial state for agents with opinions/interests on multiple issues
#' and calculates initial perceived distances between all actors.
#'
#' @param n_actors Number of actors (default: 100)
#' @param n_issues Number of issues (default: 4)
#' @param mean_interest Mean of normal distribution for interests (default: 0)
#' @param sd_interest SD of normal distribution for interests (default: 33.3)
#' @param interest_range Range for clamping interest values (default: c(-100, 100))
#'
#' @return List containing:
#' - actors: List of actor opinion vectors
#' - distances: Matrix of perceived distances between actors
initialize_opinion_model <- function(n_actors = 100,
n_issues = 4,
mean_interest = 0,
sd_interest = 33.3,
interest_range = c(-100, 100)) {
# Generate matrix of all actor opinions/interests
opinions <- matrix(
rnorm(n_actors * n_issues, mean = mean_interest, sd = sd_interest),
nrow = n_actors,
ncol = n_issues
)
# Clamp values to specified range
opinions[opinions < interest_range[1]] <- interest_range[1]
opinions[opinions > interest_range[2]] <- interest_range[2]
# Convert to list of vectors (one per actor)
actors <- split(opinions, row(opinions))
# Calculate initial perceived distances (mean Euclidean distance)
distances <- matrix(0, nrow = n_actors, ncol = n_actors)
for(i in 1:(n_actors-1)) {
for(j in (i+1):n_actors) {
# Calculate Euclidean distance between actors i and j
dist <- sqrt(sum((opinions[i,] - opinions[j,])^2))
distances[i,j] <- dist
distances[j,i] <- dist # Matrix is symmetric
}
}
# Normalize distances by dividing by maximum distance
max_dist <- max(distances)
distances <- distances / max_dist
# Return both actors and distances
list(
actors = actors,
distances = distances,
metadata = list(
n_actors = n_actors,
n_issues = n_issues,
mean_interest = mean_interest,
sd_interest = sd_interest,
interest_range = interest_range
)
)
}
initialize_opinion_model() |> str()List of 3
$ actors :List of 100
..$ 1 : num [1:4] 5.79 -21.27 50 -20.45
..$ 2 : num [1:4] 29.46 -15.26 -3.28 -40.52
..$ 3 : num [1:4] 15.9 28.8 14.5 14.5
..$ 4 : num [1:4] -33.5 -21.8 -22.1 34.9
..$ 5 : num [1:4] 10.1 -21.3 24.5 16.6
..$ 6 : num [1:4] -28.7 32.3 -44.8 27.5
..$ 7 : num [1:4] -26.88 -13.73 -49.3 -6.07
..$ 8 : num [1:4] 33.577 -0.525 21.216 34.447
..$ 9 : num [1:4] 12.09 31.75 -1.56 30.75
..$ 10 : num [1:4] 19.1 -12.6 3.5 -17
..$ 11 : num [1:4] 41.324 -0.469 12.486 -10.503
..$ 12 : num [1:4] -76.1 13.5 -47.9 -24.8
..$ 13 : num [1:4] -18.3 28.3 44 1.6
..$ 14 : num [1:4] -18.8 -27.2 29.2 92.6
..$ 15 : num [1:4] 42.2 61.4 25.5 22.7
..$ 16 : num [1:4] 18.4 -68.4 -23.5 -36.7
..$ 17 : num [1:4] 0.721 5.471 -0.493 -52.822
..$ 18 : num [1:4] 56.3 32.9 35.8 39.5
..$ 19 : num [1:4] -92.3 -20.3 34.5 -22.9
..$ 20 : num [1:4] -12.5 -75.3 -27.3 -55.3
..$ 21 : num [1:4] -16.46 -79.27 -9.98 -27.77
..$ 22 : num [1:4] -47.2 -30.3 -34.7 21.8
..$ 23 : num [1:4] 59.76 3.62 -100 30.59
..$ 24 : num [1:4] -30.7 27 -18.3 -64.6
..$ 25 : num [1:4] 15.25 -41.11 2.77 -14.09
..$ 26 : num [1:4] -1.57 -6.95 -11.5 29.23
..$ 27 : num [1:4] -13.1 98 13 34.3
..$ 28 : num [1:4] 41.71 22.15 -5.94 -1.45
..$ 29 : num [1:4] 3.22 -38.39 33.52 35.8
..$ 30 : num [1:4] -36.1 -15.3 47.5 42.4
..$ 31 : num [1:4] 35.58 25.17 25 -4.97
..$ 32 : num [1:4] -34.88 -4.95 -27.2 -20.5
..$ 33 : num [1:4] 52.93 -76.92 100 8.97
..$ 34 : num [1:4] -49.1 -56.8 73.2 30.7
..$ 35 : num [1:4] 65.93 58.43 41.03 2.18
..$ 36 : num [1:4] -15.2 28.8 55.9 26.2
..$ 37 : num [1:4] 8.59 54.81 1.46 19.92
..$ 38 : num [1:4] -42.51 30.01 4.22 -14.38
..$ 39 : num [1:4] 9.09 -25.19 40.71 29.71
..$ 40 : num [1:4] -28.9 -36.4 44.6 16
..$ 41 : num [1:4] 24.85 -55.82 -14.91 -8.49
..$ 42 : num [1:4] -56.1 -12.6 58.7 15
..$ 43 : num [1:4] 25.3 -39.9 26.7 -18.8
..$ 44 : num [1:4] -26.3 33.82 16.12 3.58
..$ 45 : num [1:4] -57.44 -5.33 34.18 14.1
..$ 46 : num [1:4] 20.65 -5.66 -1.56 -17.53
..$ 47 : num [1:4] -7.6 36.7 50.4 24.8
..$ 48 : num [1:4] -59.2 -10.2 -43.8 16.1
..$ 49 : num [1:4] 5.35 -16.01 44.91 17.25
..$ 50 : num [1:4] 31.9 -15.1 18.6 66.9
..$ 51 : num [1:4] 30 25 -50.1 -62.1
..$ 52 : num [1:4] -48.31 -7.37 14.46 20.42
..$ 53 : num [1:4] -3.22 8.92 38.3 68.16
..$ 54 : num [1:4] 1.87 -13.75 -1.37 45.16
..$ 55 : num [1:4] 50.3 39.2 -13.7 -10.8
..$ 56 : num [1:4] -27.18 -51.87 7.09 -16.76
..$ 57 : num [1:4] 17.5 44.8 34.5 -49.3
..$ 58 : num [1:4] 74.8 -17.3 12.6 -35.9
..$ 59 : num [1:4] -14.1 -39.6 -14.5 27.8
..$ 60 : num [1:4] 6.8 3.13 -100 -14.63
..$ 61 : num [1:4] 5.44 44.42 -30.57 7.62
..$ 62 : num [1:4] 78.28 -1.97 -55.29 16.33
..$ 63 : num [1:4] -2.89 77.57 24.47 30.73
..$ 64 : num [1:4] 11.6 -47.7 -42.4 75.8
..$ 65 : num [1:4] 62.7 52.7 -62.6 19.2
..$ 66 : num [1:4] -54.2 -11.9 13.4 23.7
..$ 67 : num [1:4] -21.74 -3.09 -35.66 36.3
..$ 68 : num [1:4] -51.1 -23.1 15.6 -18.4
..$ 69 : num [1:4] -41.2 -10.6 -36.7 -31.5
..$ 70 : num [1:4] -20.4 -7.41 29.13 -36.51
..$ 71 : num [1:4] -6.71 100 7.44 -7.19
..$ 72 : num [1:4] 7.57 34.05 -48.73 -10.89
..$ 73 : num [1:4] 12 -28.9 13.5 28.2
..$ 74 : num [1:4] -4.62 -22.48 7.01 -52.04
..$ 75 : num [1:4] -27.1 -12.7 59.9 -14.2
..$ 76 : num [1:4] -33.9 -14 41.4 63.8
..$ 77 : num [1:4] 48.23 -29.1 -2.29 67.14
..$ 78 : num [1:4] 4.45 11.57 -14.68 24.87
..$ 79 : num [1:4] 33.4 -16.6 26.9 -27.6
..$ 80 : num [1:4] -7.64 75.04 16.08 50.74
..$ 81 : num [1:4] -8.37 -4.68 27.7 -68.07
..$ 82 : num [1:4] -58.2 69.5 30.2 19.2
..$ 83 : num [1:4] -14.2 -34.3 -37.5 -10.7
..$ 84 : num [1:4] -12.8 18.3 -43.1 -41.2
..$ 85 : num [1:4] -21.84 -5.39 -3.23 16.16
..$ 86 : num [1:4] 17.4 10.4 -31.5 46.6
..$ 87 : num [1:4] 28.59 -24.94 -7.88 35.02
..$ 88 : num [1:4] 29.9 -13.2 -14.6 -62.3
..$ 89 : num [1:4] 44.6 -15.1 -11 34.9
..$ 90 : num [1:4] -41.4 -15 54 64.8
..$ 91 : num [1:4] 24.07 24.68 6.06 35
..$ 92 : num [1:4] 2.8149 15.7477 -46.1642 0.0802
..$ 93 : num [1:4] 7.55 -47.49 -9.79 -20.49
..$ 94 : num [1:4] -13.7 25.6 38.7 -28.6
..$ 95 : num [1:4] -7.75 15.48 29.15 -2.76
..$ 96 : num [1:4] 49.59 -9.39 19.86 25.69
..$ 97 : num [1:4] 21.7 -41.1 54.5 -40
..$ 98 : num [1:4] -1.85 -26.33 -38.99 -5.06
..$ 99 : num [1:4] 36.8 -13 -22.9 -22.4
.. [list output truncated]
$ distances: num [1:100, 1:100] 0 0.28 0.322 0.447 0.204 ...
$ metadata :List of 5
..$ n_actors : num 100
..$ n_issues : num 4
..$ mean_interest : num 0
..$ sd_interest : num 33.3
..$ interest_range: num [1:2] -100 100Process overview and scheduling
Describe the processes (actions) within the model and the order in which they are performed. This can happen in fairly coarse terms. Also specify the schedule (in which order the processes are performed). When you code your model, you can easily interpret and implement the singular steps as functions. This will make your code very readable and comprehensive.
An action is described in terms of an entity that executes a process or behavior that changes certain state variables. Those processes within the action are performed in a certain order. Those actions are listed in submodels, which are to be described in further detail in a later part.
You need to include everything that is completed at each time step, and describe all variables that might be affected by that. Moreover, if an action is performed by more than one entity, you need to specify the order. The schedule summary has to be clear about when the variables are updated (it helps to look at the former section where you specified all the state variables).
Furthermore, you should explain why you included those processes and scheduled them in the manner you did. Feel free to provide a flow chart or pseudo code to illustrate the schedule.
Your model might contain discrete events, an intervention or so. Make sure to include how those are scheduled.
Process overview and scheduling in Baldassarri and Bearman (2007):
Each round a random sample of potential interlocutors is drawn for each actor. The size of the sample is proportional to the actor’s overall level of interest. This follows from the assumption that “the more one is committed to a cause, the more likely one is to start a conversation.” (p. 790) People have a tendency for homophily with regard to their social contacts. Hence, actors choose the ones they want to deliberate with based on their overall ideological proximity. However, they do not exclusively communicate with the ones they are similar to, there is still some room for communication with ideologically dissimilar ones – those interactions happen less often though. In the beginning, actors do not know about others’ ideological stance. They learn it through interaction.
The process of interpersonal influence looks as follows: first, the issue for discussion is chosen based on the cumulative interest of both actors. Second, the new opinions of both actors towards the chosen issue are computed and modified. Those can either be reinforced or become more neutral. Individuals which share the same position on the issue reinforce each others’ opinions, whereas people with diverging views may either find a compromise (if they are similar on other dimensions), leading to opinions closer on the ideology scale, or indulge in further conflict, where their opinions grow further apart from each other. This affects the new overall level of interest of both users as well as their ideological distance between them.
Design concepts
Here, you need to relate your model to 11 common concepts in ABM. This is useful to place it within the ABM literature. A more conclusive description can be found in the supplemental material of Grimm et al. (2020).
- basic principles: how does the model relate to existing approaches, how are they implemented or taken into account? Is there new literature included that has not been implemented yet?
- emergence: which model results stem from which mechanisms, which are imposed by rules, why are some results more or less emergent?
- adaptation: what decisions are agents making in response to what stimuli; which alternatives can they choose from, the variables that affect the decision, how do they make the decision – direct or indirect objective seeking
- learning: if agents change their decision-making based on prior “experience”
- prediction: do agents try to foresee future outcomes and adapt their decisions to this
- sensing: does an agent get to know other entities state variables; usually it’s assumed that they have full information, but the sensing process might give them not perfect information
- interactions: are agents interacting and how (direct or mediated)?
- stochasticity: if you draw numbers at any place from some sort of stochastic distribution – why and how?
- collectives: groups of agents – either through (implicit) emergence or through determination (e.g., political parties); are they included, how, and what are the consequences?
- observation: how is information collected and summarized/analyzed?
Design concepts of Baldassarri and Bearman (2007):
- basic principles: “Models that involve dynamics of interpersonal influence differ broadly in their scope, ranging from the study of dynamics of ideological polarization (Hegselmann and Krause 2002; Macy et al. 2003; Nowak et al. 1990), collective action (Kim and Bearman 1997), and collective decision-making (Marsden 1981) to the persistence of cultural differences (Axelrod 1997) and political disagreement (Huckfeldt, Johnson, and Sprague 2004). Our goal has been to deploy a model of interpersonal influence sensitive to dynamics of political discussion, where actors hold multiple opinions on diverse issues, interact with others relative to the intensity and orientation of their political preferences, and through evolving discussion networks shape their own and others’ political contexts. In the model, opinion change depends on two factors: the selection of interaction partners, which determines the aggregate structure of the discussion network, and the process of interpersonal influence, which determines the dynamics of opinion change.” (p. 788)
- emergence: through agents’ interactions and the opinion changes those might encompass
- adaptation: agents have an engrained tendency to prefer similar others and avoid conflict
- learning: agents learn about their peers’ opinions which subsequently alters the probibility of contact
- prediction: not applicable
- interactions: agents communicate bidirectional – discourse leads to opinion changes in both agents
- sensing: agents have full information on other agents’ ideology
- stochasticity: agents’ interlocutors are chosen at random, the number of potential interlocutors is based on political interest though; a Bernoulli process determines, whether they actually talk to each other, depending on their ideological similarity; the initial distribution of opinions is determined through a normal distribution
- collectives: not applicable
- observation: state variables are updated after every interaction; eventually, takeoff cases are identified through the Herfindahl-Hirschman index; networks are qualitatively interpreted with regard to the dominating topics; an index of polarization is computed based on the dispersion and bimodality of the distribution of opinions to uncover relative levels of polarization; modularity is used to assess how polarized the network is (i.e., how well partitioning the network into two clusters works); finally, it is determined how homogeneous the networks for each individual appear and whether this differs for takeoff and non-takeoff cases.
Initialization
In the final three parts of the ODD protocol, you really need to go into detail with the model. In the first part, you describe the initialization: what are the entities that are created, how many of them – and why this number, and what values are given to state values. Perhaps, are there locations/collectives set; is there specific data used to create the agents, the space, or the parameters beforehand, where do they come from and are there potential pitfalls/biases? Are there different initialization scenarios – if so, why?
In here, the most important thing is the why: what drives your decisions here. Include relevant references and justify your decisions.
Initialization in Baldassarri and Bearman (2007):
the model consists of 100 actors. Those hold opinions on 4 issues. The authors do not provide justifications for why they chose exactly 100 actors and 4 issues. Those opinions are not only opinions but also serve as indicators of the actor’s interest towards the particular topic. They argue that this is a reasonable assumption since prior research has consistently shown that people with stronger interest in a topic also usually have stronger opinions. Opinions on each topic are independent from each other and drawn from a normal distribution with mean 0 and standard deviation 33.3. Moreover, each agent gets an initial value for the perceived distance to their peers. It’s the demeaned euclidean distance (normalized by division by max(actual_distances)) between all actors.
There are no different initialization scenarios.
#' Initialize opinion dynamics model
#'
#' @param n_actors Number of actors
#' @param n_issues Number of issues
#' @param mean_interest Mean of opinion distribution
#' @param sd_interest SD of opinion distribution
#' @param interest_range Range for opinions
initialize_model <- function(n_actors = 100,
n_issues = 4,
mean_interest = 0,
sd_interest = 33.3,
interest_range = c(-100, 100)) {
# Generate opinions
opinions <- matrix(
rnorm(n_actors * n_issues, mean = mean_interest, sd = sd_interest),
nrow = n_actors,
ncol = n_issues
)
# Clamp values to range
opinions[opinions < interest_range[1]] <- interest_range[1]
opinions[opinions > interest_range[2]] <- interest_range[2]
# Convert to list of vectors
actors <- split(opinions, row(opinions))
# Calculate initial distances
distances <- matrix(0, nrow = n_actors, ncol = n_actors)
for(i in 1:(n_actors-1)) {
for(j in (i+1):n_actors) {
dist <- sqrt(sum((opinions[i,] - opinions[j,])^2))
distances[i,j] <- dist
distances[j,i] <- dist
}
}
# Normalize distances
distances <- distances / max(distances)
# Initialize perceived distances and interaction history
perceived_distances <- matrix(mean(distances[upper.tri(distances)]),
nrow = n_actors,
ncol = n_actors)
diag(perceived_distances) <- 0
interaction_history <- matrix(NA_integer_,
nrow = n_actors,
ncol = n_actors)
diag(interaction_history) <- 0
list(
actors = actors,
actual_distances = distances,
perceived_distances = perceived_distances,
interaction_history = interaction_history,
metadata = list(
n_actors = n_actors,
n_issues = n_issues,
mean_interest = mean_interest,
sd_interest = sd_interest,
interest_range = interest_range
)
)
}Input data
Do you use empirically observed data to calibrate your model? Those data can affect state variables that might change over time. Parameters and everything else used to initially set up the world needs to be specified in step 5, initialization, however.
Input data in Baldassarri and Bearman (2007):
No.
Submodels
In the final part, you need to go back to the schedule and describe each step and its submodels thoroughly. A thorough description encompasses its “equations, algorithms, parameters, and parameter values.” (Grimm et al. 2020, Supp. 1: 27) Also justify why you have made those design decisions. Include robustness checks that take into account scenarios the submodels might encounter.
Submodels in Baldassarri and Bearman (2007):
In the following, I neither include robustness checks nor thorough or complete theoretical motivation. However, I include workable code that can be put in, e.g., a loop to run the model.
The first submodel is the selection of interaction partners: “for each actor at each time period t, we randomly selected from the population a number of potential interlocutors as a function of the actor’s overall level of interest. The number of people selected is proportional to the sum of the squared mean of interest over the four issues … the probability of interaction is proportional to their interest and an inverse function of the perceived ideological distance between the two.” (p. 791)
\(\lambda\) is the distance between two actors. Initially, it is the demeaned euclidean distance (normalized by division by max(euclidean_distance)) between all actors. As actors communicate with each other, they learn about their views and update their distance to their actual distance \[d_{ab}^{(t)}=\frac{\sqrt{\sum\limits_{i=1}^{4} (a_{i}^{(t)}-b_{i}^{(t)})^{2}}}{\max_{\{a,b\}\in N}\left[\sqrt{\sum\limits_{i=1}^{4}(a_{i}^{(t)}-b_{i}^{(t)})^{2}} \right]}\]
So, in my own words: each round a random sample of potential interlocutors is drawn for each actor. The size of the sample is proportional to the actor’s overall level of interest. This follows from the assumption that “the more one is committed to a cause, the more likely one is to start a conversation.” (p. 790) People have a tendency for homophily with regard to their social contacts. Hence, actors choose the ones they want to deliberate with based on their overall ideological proximity. However, they do not exclusively communicate with the ones they are similar to, there is still some room for communication with ideologically dissimilar ones – those interactions happen less often though. In the beginning, actors do not know about others’ ideological stance. They learn it through interaction.
#' Calculate interaction probability
#'
#' @param interest_a First actor's interest
#' @param interest_b Second actor's interest
#' @param perceived_distance Perceived distance between actors
#' @param eta Scaling factor
calculate_interaction_probability <- function(interest_a,
interest_b,
perceived_distance,
eta = 0.005) {
(eta * (interest_a * interest_b) / 100) * (1 - perceived_distance)
}Finally, once the interlocutors are chosen, agents need to deliberate. First, the issue that is of the highest cumulative interest to the speakers is chosen:
#' Select discussion issue
#'
#' @param model Current model state
#' @param actor_a First actor
#' @param actor_b Second actor
select_discussion_issue <- function(model, actor_a, actor_b) {
opinions_a <- model$actors[[actor_a]]
opinions_b <- model$actors[[actor_b]]
issue_interests <- tibble(
issue = seq_along(opinions_a),
interest_a = abs(opinions_a),
interest_b = abs(opinions_b),
cumulative_interest = interest_a + interest_b
) %>%
filter(cumulative_interest == max(cumulative_interest)) %>%
slice_sample(n = 1)
list(
issue_index = issue_interests$issue,
opinion_a = opinions_a[issue_interests$issue],
opinion_b = opinions_b[issue_interests$issue],
interest_a = issue_interests$interest_a,
interest_b = issue_interests$interest_b,
cumulative_interest = issue_interests$cumulative_interest,
same_sign = sign(opinions_a[issue_interests$issue]) ==
sign(opinions_b[issue_interests$issue])
)
}Finally, once actors have found each other and chosen an issue to discuss, we can let them deliberate. For this, we first compute the change, then the direction.
The former is calculated as follows: “we model opinion change as inversely proportional to one’s level of interest. In sum, changes in people’s opinions are incremental and sensitive to their level of interest—the magnitude of change decreases as actors’interest (positive or negative) increases. Formally, \[\Delta a_i^{(t)} = \mu \times \frac{||a_i^{(t)}| - |b_i^{(t)}||}{|a_i^{(t)}|} \text{ for } a_i^{(t)} \neq 0\] where \(\mu\) is a scaling factor (.1) that restricts the range of attitude change given an interaction.”
Opinion changes work like this (see p. 792):
- if they share the opinion on the discussed topic (i.e., they have the same sign), their opinions are reinforced.
- if they do not have the same signs (read: views) on the discussed topic yet agree on all the other topics, their opinions on the focal topic will go closer together.
- if neither of the former is the case, their own views on the topic will be reinforced and their overall distance increase.
After the interaction, the distances between actors (now that they have interacted, they “know” the true values) are updated. Hence, an agent can change their opinion multiple times in each step, depending on how many interlocutors they have.
#' Calculate opinion changes
#'
#' @param opinion_a First actor's opinion
#' @param opinion_b Second actor's opinion
#' @param should_compromise Whether to compromise
calculate_opinion_changes <- function(opinion_a, opinion_b, should_compromise) {
delta_a <- 0.1 * abs((abs(opinion_a) - abs(opinion_b)) / abs(opinion_a))
delta_b <- 0.1 * abs((abs(opinion_b) - abs(opinion_a)) / abs(opinion_b))
sign_a <- sign(opinion_a)
sign_b <- sign(opinion_b)
if(sign_a == sign_b) {
change_a <- delta_a * sign_a
change_b <- delta_b * sign_b
} else {
if(should_compromise) {
change_a <- -delta_a * sign_a
change_b <- -delta_b * sign_b
} else {
change_a <- delta_a * sign_a
change_b <- delta_b * sign_b
}
}
list(
change_a = change_a,
change_b = change_b,
delta_a = delta_a,
delta_b = delta_b
)
}
#' Calculate Euclidean distance between two actors
#'
#' @param opinions_a Vector of first actor's opinions
#' @param opinions_b Vector of second actor's opinions
#' @return Euclidean distance between actors
calculate_euclidean_distance <- function(opinions_a, opinions_b) {
sqrt(sum((opinions_a - opinions_b)^2))
}
#' Update distances after deliberation
#'
#' @param model Current model state
#' @param actor_a First actor index
#' @param actor_b Second actor index
#' @param current_time Current simulation time
#' @return Updated model with new distances
update_distances_after_deliberation <- function(model,
actor_a,
actor_b,
current_time) {
# Calculate new actual distance
new_distance <- calculate_euclidean_distance(
model$actors[[actor_a]],
model$actors[[actor_b]]
)
# Normalize by current maximum distance
current_max_dist <- max(model$actual_distances)
new_normalized_distance <- new_distance / current_max_dist
# Update actual distances (symmetric)
model$actual_distances[actor_a, actor_b] <- new_normalized_distance
model$actual_distances[actor_b, actor_a] <- new_normalized_distance
# Update perceived distances to match actual distance after interaction
model$perceived_distances[actor_a, actor_b] <- new_normalized_distance
model$perceived_distances[actor_b, actor_a] <- new_normalized_distance
# Update interaction history
model$interaction_history[actor_a, actor_b] <- current_time
model$interaction_history[actor_b, actor_a] <- current_time
model
}
#' Process full deliberation including opinion and distance updates
#'
#' @param model Current model state
#' @param deliberation Deliberation details
#' @param current_time Current simulation time
#' @return Updated model and deliberation results
process_deliberation_with_distances <- function(model,
deliberation,
current_time) {
# First process opinion changes
opinion_result <- process_opinion_changes(model, deliberation)
# Then update distances
updated_model <- update_distances_after_deliberation(
opinion_result$model,
deliberation$actors[1],
deliberation$actors[2],
current_time
)
# Return complete results
list(
model = updated_model,
opinion_changes = opinion_result$changes,
type = opinion_result$type,
distance_before = model$actual_distances[deliberation$actors[1],
deliberation$actors[2]],
distance_after = updated_model$actual_distances[deliberation$actors[1],
deliberation$actors[2]],
deliberation_details = deliberation
)
}
#' Update distances after deliberation
#'
#' @param model Current model state
#' @param actor_a First actor
#' @param actor_b Second actor
#' @param current_time Current time
update_distances <- function(model, actor_a, actor_b, current_time) {
new_distance <- sqrt(sum((unlist(model$actors[[actor_a]]) -
unlist(model$actors[[actor_b]]))^2))
new_normalized_distance <- new_distance / max(model$actual_distances)
model$actual_distances[actor_a, actor_b] <- new_normalized_distance
model$actual_distances[actor_b, actor_a] <- new_normalized_distance
model$perceived_distances[actor_a, actor_b] <- new_normalized_distance
model$perceived_distances[actor_b, actor_a] <- new_normalized_distance
model$interaction_history[actor_a, actor_b] <- current_time
model$interaction_history[actor_b, actor_a] <- current_time
model
}
#' Run one step of simulation
#'
#' @param model Current model state
#' @param current_time Current time step
#' @param eta Interaction probability scaling factor
run_step <- function(model, current_time, eta = 0.005) {
n_actors <- model$metadata$n_actors
# Calculate interest levels
interest_levels <- map_dbl(model$actors, ~mean(abs(.))^2)
# Generate potential interactions
interactions <- expand_grid(
actor_a = 1:n_actors,
actor_b = 1:n_actors
) %>%
filter(actor_a != actor_b) %>%
mutate(
interest_a = interest_levels[actor_a],
interest_b = interest_levels[actor_b],
perceived_distance = map2_dbl(
actor_a,
actor_b,
~model$perceived_distances[.x, .y]
),
prob = pmap_dbl(
list(
interest_a = interest_a,
interest_b = interest_b,
perceived_distance = perceived_distance
),
calculate_interaction_probability,
eta = eta
),
will_interact = map_lgl(prob, ~rbernoulli(1, .x))
) %>%
filter(will_interact)
# Process each interaction
for(i in 1:nrow(interactions)) {
actor_a <- interactions$actor_a[i]
actor_b <- interactions$actor_b[i]
# Select issue
issue <- select_discussion_issue(model, actor_a, actor_b)
# Check other issues for compromise decision
other_issues <- setdiff(seq_along(model$actors[[1]]), issue$issue_index)
other_opinions_same_sign <- map_lgl(other_issues, function(j) {
sign(model$actors[[actor_a]][j]) == sign(model$actors[[actor_b]][j])
})
should_compromise <- all(other_opinions_same_sign)
# Calculate and apply opinion changes
changes <- calculate_opinion_changes(
issue$opinion_a,
issue$opinion_b,
should_compromise
)
# Update opinions
model$actors[[actor_a]][issue$issue_index] <- issue$opinion_a + changes$change_a
model$actors[[actor_b]][issue$issue_index] <- issue$opinion_b + changes$change_b
# Update distances
model <- update_distances(model, actor_a, actor_b, current_time)
}
list(
model = model,
n_interactions = nrow(interactions),
interactions = interactions
)
}Now that we have all the necessary functions and can implement the full model.
#' Run complete simulation
#'
#' @param max_steps Maximum number of steps
#' @param n_actors Number of actors
#' @param n_issues Number of issues
#' @param plot Whether to plot results
run_simulation <- function(max_steps = 500,
n_actors = 100,
n_issues = 4,
plot = TRUE) {
# Initialize
model <- initialize_model(n_actors = n_actors, n_issues = n_issues)
# Storage for results
results <- vector("list", max_steps)
# Run simulation
for(step in 1:max_steps) {
result <- run_step(model, current_time = step)
model <- result$model
results[[step]] <- list(
n_interactions = result$n_interactions,
distances = model$actual_distances,
opinions = model$actors
)
}
list(
final_state = model,
history = results
)
}
# Example usage
set.seed(123)
sim_result <- run_simulation(
max_steps = 100,
n_actors = 100,
n_issues = 4
)Warning: There was 1 warning in `mutate()`.
ℹ In argument: `will_interact = map_lgl(prob, ~rbernoulli(1, .x))`.
Caused by warning:
! `rbernoulli()` was deprecated in purrr 1.0.0.system.time({
sim_result <- run_simulation(max_steps = 10, n_actors = 100, plot = FALSE)
}) user system elapsed
45.849 0.273 46.729 Further links
- It is often advisable to draw on former work instead of developing an ABM from scratch (but make sure to cite the models properly!). This bookdown book contains some information. And this one as well!
- Following the ODD protocol closely during the creation and report of an ABM is key. This website provides a vast amount of resources and hands-on tutorials
References
Baldassarri, Delia and Peter S. Bearman. 2007. “Dynamics of Political Polarization.” American Sociological Review 72(5):784–811.
Edmonds, Bruce, Christophe Le Page, Mike Bithell, Edmund Chattoe-Brown, Volker Grimm, Ruth Meyer, Cristina Montañola-Sales, Paul Ormerod, Hilton Root, and Flaminio Squazzoni. 2019. “Different Modelling Purposes.” Journal of Artificial Societies and Social Simulation 22(3):6.
Grimm, Volker, Steven F. Railsback, Christian E. Vincenot, Uta Berger, Cara Gallagher, Donald L. DeAngelis, Bruce Edmonds, Jiaqi Ge, Jarl Giske, Jürgen Groeneveld, Alice S. A. Johnston, Alexander Milles, Jacob Nabe-Nielsen, J. Gareth Polhill, Viktoriia Radchuk, Marie-Sophie Rohwäder, Richard A. Stillman, Jan C. Thiele, and Daniel Ayllón. 2020. “The ODD Protocol for Describing Agent-Based and Other Simulation Models: A Second Update to Improve Clarity, Replication, and Structural Realism.” Journal of Artificial Societies and Social Simulation 23(2):7.