needs(sf, tidyverse, tigris, maps, janitor, RColorBrewer, classInt, spatialreg, spdep)Chapter 17: Inference with Spatial Data
This tutorial demonstrates how to do statistical inference with spatial data in R, specifically focusing on analyzing data on child poverty in the U.S. South1. This tutorial will cover different types of spatial models and how to interpret them, as well as helper functions on which model to choose. Statistical inference will be performed using the spatialreg package. e
Data preparation
us_counties <- counties(cb = TRUE, resolution = "20m", year = 2016, progress_bar = FALSE) |>
st_transform(5070) |>
mutate(FIPS = str_c(STATEFP, COUNTYFP))
child_pov <- read_csv("https://raw.githubusercontent.com/chrismgentry/Spatial-Regression/master/Data/childpov18_southfull.csv") |>
mutate(FIPS = as.character(FIPS),
FIPS = case_when(
str_length(FIPS) == 4 ~ str_c("0", FIPS),
TRUE ~ FIPS
))
us_counties_child_pov <- left_join(us_counties, child_pov, by = "FIPS") |>
clean_names() |>
drop_na(x2016_child_poverty)
breaks <- classIntervals(us_counties_child_pov$x2016_child_poverty,
n = 7,
style = "jenks")
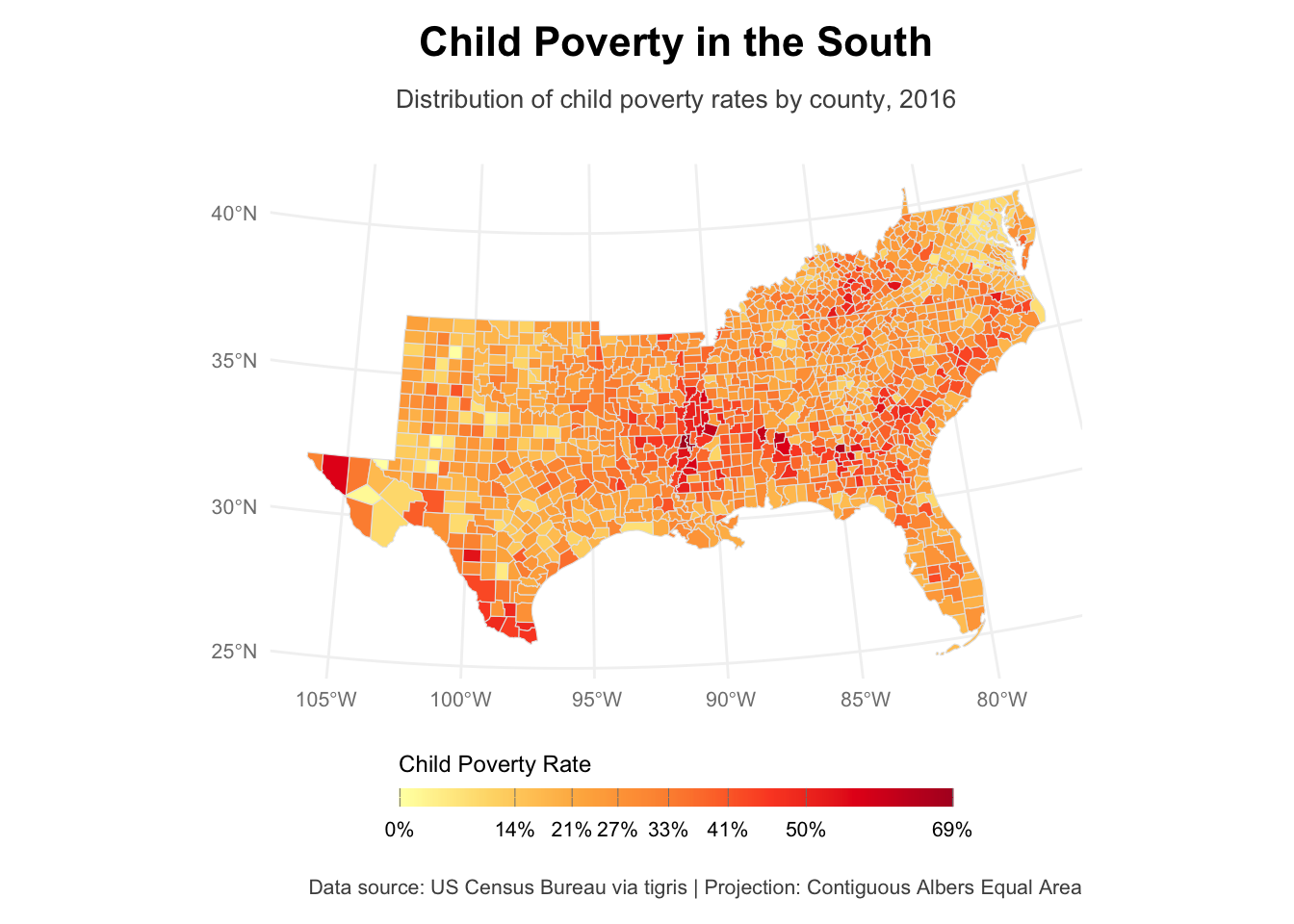
us_counties_child_pov |>
ggplot() +
geom_sf(aes(fill = x2016_child_poverty),
color = "gray90",
size = 0.1) +
scale_fill_gradientn(
colors = brewer.pal(7, "YlOrRd"),
breaks = round(breaks$brks, 1),
labels = function(x) paste0(round(x, 0), "%"), # Round to whole numbers
name = "Child Poverty Rate",
guide = guide_colorbar(
direction = "horizontal",
title.position = "top",
label.position = "bottom",
barwidth = 15,
barheight = 0.5,
ticks.colour = "gray50"
)
) +
theme_minimal() +
theme(
plot.title = element_text(hjust = 0.5,
size = 16,
face = "bold",
margin = margin(b = 10)),
plot.subtitle = element_text(hjust = 0.5,
size = 10,
color = "gray30",
margin = margin(b = 20)),
plot.caption = element_text(color = "gray30",
size = 8,
margin = margin(t = 10)),
legend.position = "bottom",
legend.title = element_text(size = 9),
legend.text = element_text(size = 8),
axis.text = element_text(size = 8, color = "gray50"),
panel.grid = element_line(color = "gray95"),
plot.margin = margin(10, 10, 10, 10)
) +
labs(
title = "Child Poverty in the South",
subtitle = "Distribution of child poverty rates by county, 2016",
caption = "Data source: US Census Bureau via tigris | Projection: Contiguous Albers Equal Area"
)
Modeling Child Poverty in the South
Let’s move on to statistically explain child poverty in the South. The data set contains some variables that might matter in this case. In particular, there is information on race composition (i.e., the share of Blacks and Latinx people), the composition of the labor market (i.e., different sectors), unemployment, single motherhood, unmarried people, share of people with less than a high school degree, and the share of uninsured people.
OLS
We’ll throw all these in a first OLS model with child poverty as the dependent variable, not taking into account any spatial variables. The independent variables are logged using the natural logarithm when appropriate to ensure a more normal distribution.
ols_mod <- lm(x2016_child_poverty ~ lnmanufacturing + lnretail + lnhealthss + lnconstruction +
lnlesshs + lnunemployment + lnsinglemom + lnuninsured + lnteenbirth +
lnincome_ratio + lnunmarried + lnblack + lnhispanic,
data = us_counties_child_pov)
ols_mod |> summary()
Call:
lm(formula = x2016_child_poverty ~ lnmanufacturing + lnretail +
lnhealthss + lnconstruction + lnlesshs + lnunemployment +
lnsinglemom + lnuninsured + lnteenbirth + lnincome_ratio +
lnunmarried + lnblack + lnhispanic, data = us_counties_child_pov)
Residuals:
Min 1Q Median 3Q Max
-29.801 -3.640 -0.222 3.652 25.087
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -68.15371 4.13232 -16.493 < 2e-16 ***
lnmanufacturing -0.08985 0.25604 -0.351 0.725706
lnretail -2.33578 0.63934 -3.653 0.000268 ***
lnhealthss 1.85976 0.94160 1.975 0.048450 *
lnconstruction -2.61641 0.47560 -5.501 4.47e-08 ***
lnlesshs 8.49402 0.65982 12.873 < 2e-16 ***
lnunemployment 10.94179 0.74092 14.768 < 2e-16 ***
lnsinglemom 3.81557 0.49541 7.702 2.51e-14 ***
lnuninsured 8.79707 1.05484 8.340 < 2e-16 ***
lnteenbirth 0.78850 0.44553 1.770 0.076976 .
lnincome_ratio 8.92817 1.42606 6.261 5.08e-10 ***
lnunmarried 0.83874 0.21659 3.873 0.000113 ***
lnblack 0.17175 0.12152 1.413 0.157767
lnhispanic -1.03569 0.16423 -6.306 3.82e-10 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 6.273 on 1408 degrees of freedom
Multiple R-squared: 0.6396, Adjusted R-squared: 0.6363
F-statistic: 192.2 on 13 and 1408 DF, p-value: < 2.2e-16Success. Our model fits quite well already, explaining almost 64 percent of the variance.
However, as we saw in the map above, there seemed to be certain hot spots of child poverty. Hence, we see significant autocorrelation in the data – counties next to each other might experience similar child poverty due to them being situated close by. Remember Tobler’s first law of Geography “everything is related, but near things are more related than distant things”. Whether this is indeed the case can be confirmed using Moran’s I.
us_counties_child_pov <- us_counties_child_pov |>
st_make_valid()
counties_nb <- poly2nb(us_counties_child_pov, queen = TRUE)
counties_weights <- nb2listw(counties_nb, style = "W", zero.policy = TRUE)
morans_i_child_pov <- moran.test(us_counties_child_pov$x2016_child_poverty,
counties_weights,
zero.policy = TRUE)
morans_i_child_pov
Moran I test under randomisation
data: us_counties_child_pov$x2016_child_poverty
weights: counties_weights
Moran I statistic standard deviate = 27.707, p-value < 2.2e-16
alternative hypothesis: greater
sample estimates:
Moran I statistic Expectation Variance
0.4464913831 -0.0007037298 0.0002605015 Indeed, we see high autocorrelation when it comes to child poverty. For our regression analysis, this will result in unequal accuracy of our predictions – i.e., predictive quality might not be accurate for certain, closely situated counties. Their residuals will be autocorrelated – residuals are defined as \[r_i = y_i - \hat{y}_i\]. Let’s check their distribution on the map and see whether they show significant autocorrelation.
us_counties_child_pov_res <- us_counties_child_pov |>
mutate(residuals = residuals(ols_mod))
breaks_res <- classIntervals(us_counties_child_pov_res$residuals,
n = 7,
style = "jenks")
us_counties_child_pov_res |>
ggplot() +
geom_sf(aes(fill = residuals),
color = "gray90",
size = 0.1) +
scale_fill_gradientn(
colors = brewer.pal(7, "BuPu"),
breaks = round(breaks_res$brks, 1),
labels = function(x) paste0(round(x, 0), "%"), # Round to whole numbers
name = "Child Poverty Rate",
guide = guide_colorbar(
direction = "horizontal",
title.position = "top",
label.position = "bottom",
barwidth = 15,
barheight = 0.5,
ticks.colour = "gray50"
)
) +
theme_minimal() +
theme(
plot.title = element_text(hjust = 0.5,
size = 16,
face = "bold",
margin = margin(b = 10)),
plot.subtitle = element_text(hjust = 0.5,
size = 10,
color = "gray30",
margin = margin(b = 20)),
plot.caption = element_text(color = "gray30",
size = 8,
margin = margin(t = 10)),
legend.position = "bottom",
legend.title = element_text(size = 9),
legend.text = element_text(size = 8),
axis.text = element_text(size = 8, color = "gray50"),
panel.grid = element_line(color = "gray95"),
plot.margin = margin(10, 10, 10, 10)
) +
labs(
title = "OLS Residuals",
subtitle = "Purple indicates over-prediction, Blue indicates under-prediction")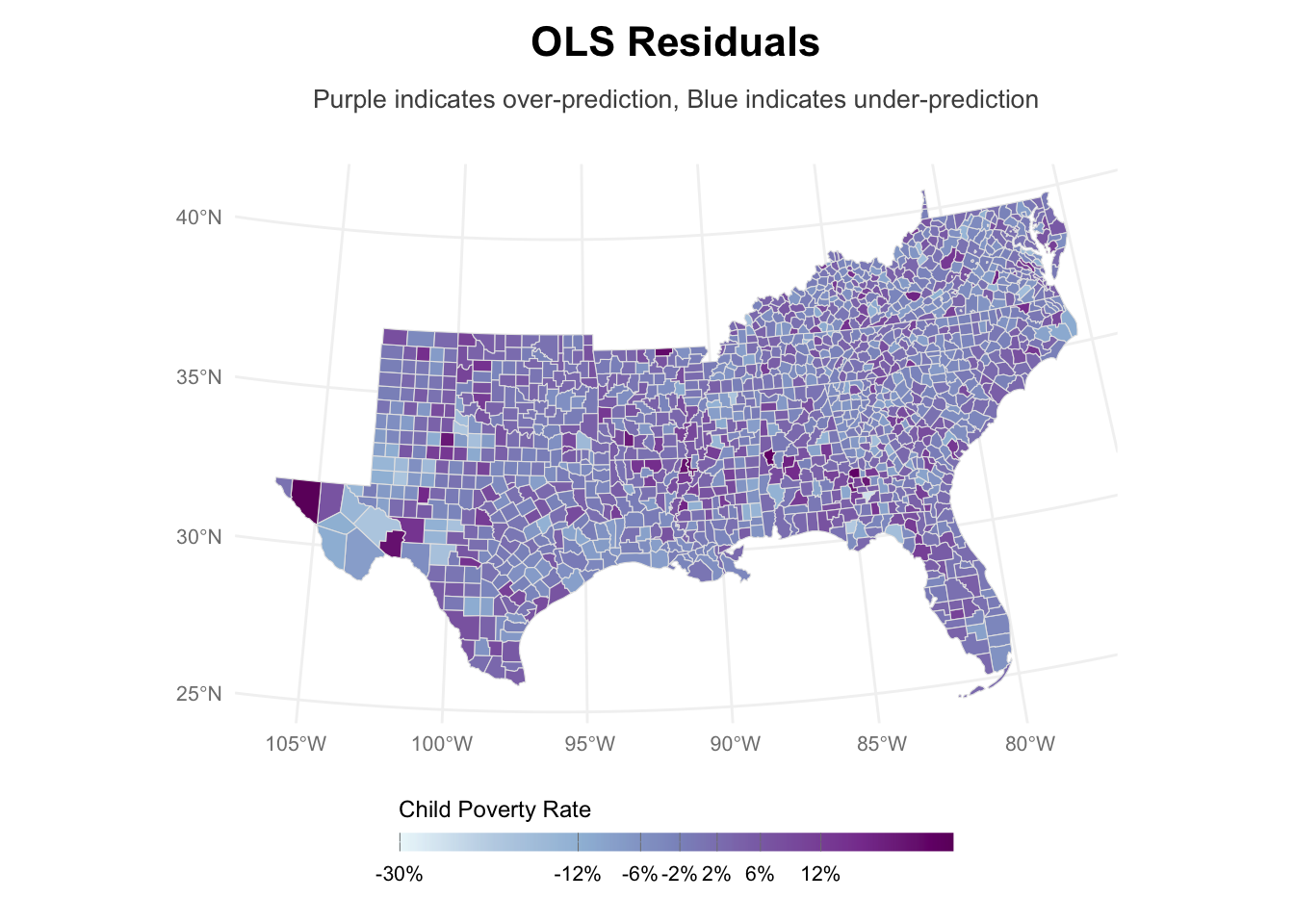
Let’s check for autocorrelation, this time of the residuals in the results.
morans_i_child_pov_res <- moran.test(us_counties_child_pov_res$residuals,
counties_weights,
zero.policy = TRUE)
morans_i_child_pov_res
Moran I test under randomisation
data: us_counties_child_pov_res$residuals
weights: counties_weights
Moran I statistic standard deviate = 6.4068, p-value = 7.43e-11
alternative hypothesis: greater
sample estimates:
Moran I statistic Expectation Variance
0.1026694504 -0.0007037298 0.0002603354 Again, there is some significant autocorrelation at play, rendering our model quite useless for prediction due to neglecting spatial relationships in our data. These relationships supposedly drive child poverty, and neglecting them is arguably like leaving out an important explanatory variable, hence our model suffers from omitted variable bias. We can look at hotspots of over- or under-prediction using a LISA map.
local_morans_resid <- localmoran(us_counties_child_pov_res$residuals,
counties_weights,
zero.policy = TRUE)
us_counties_child_pov_res <- us_counties_child_pov_res |>
mutate(
local_i_resid = local_morans_resid[, "Ii"],
local_i_p_resid = local_morans_resid[, "Pr(z != E(Ii))"]
)
ggplot(us_counties_child_pov_res) +
geom_sf(aes(fill = local_i_resid), color = "gray70", size = 0.1) +
scale_fill_gradient2(
low = "blue", mid = "white", high = "red",
midpoint = 0,
name = "Local Moran's I\nof Residuals"
) +
theme_minimal() +
labs(
title = "Local Moran's I of Residuals",
subtitle = "Spatial Clustering of Model Residuals"
)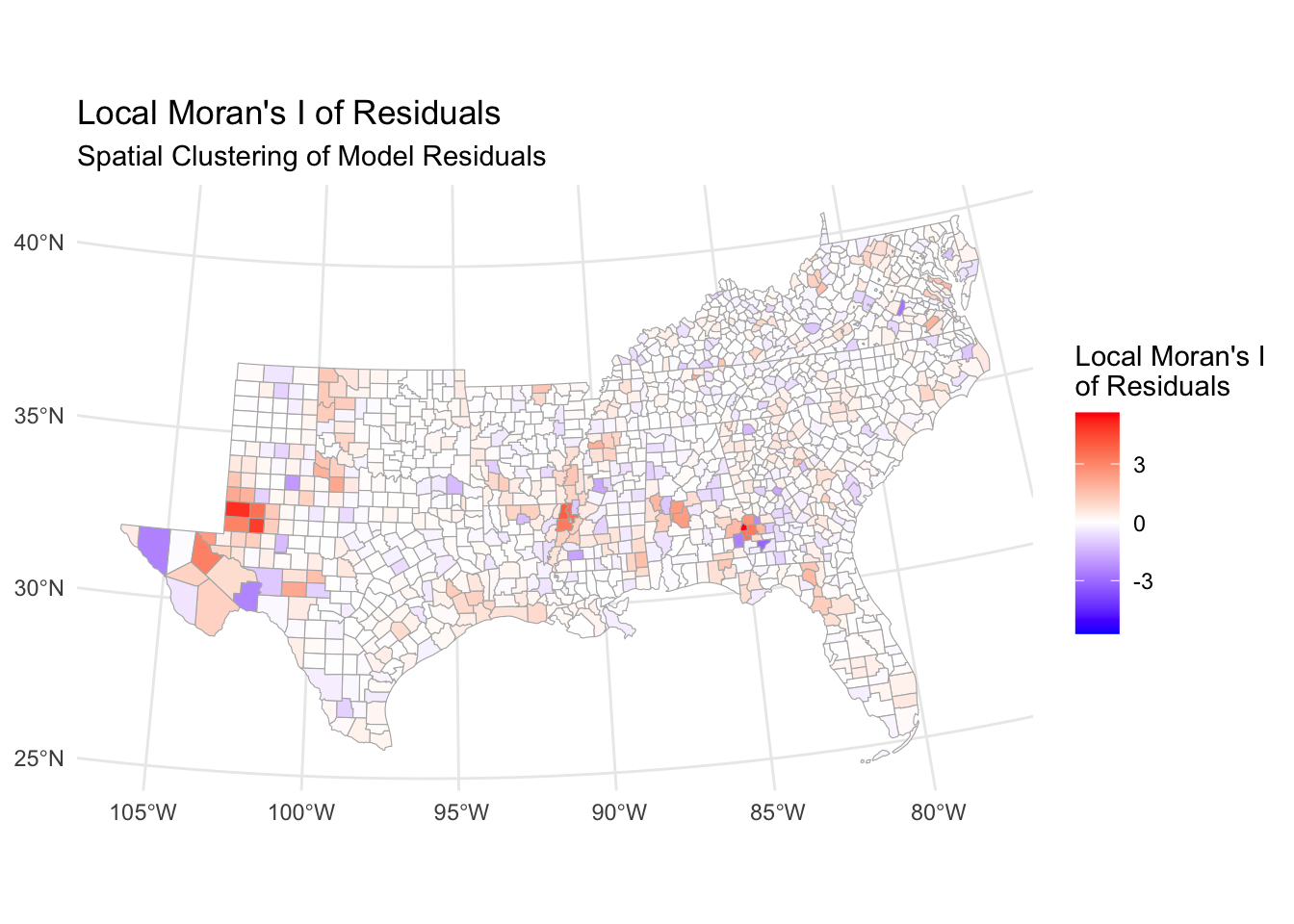
It seems that there are indeed some hot and cold spots where the basic OLS model performs particularly bad.
Spatial Regression models
Luckily, we can alleviate this by taking into account spatial relationships between counties. This is typically achieved by either including spatial lag variables – taking into account characteristics from neighboring counties to account for them having an impact on the focal county – or including an error term that captures systematically the error that may arise due to spatial autocorrelation.
In the following section we will go through different models that we can use for inference using spatial data. Each model subsection will include an explainer of the model, how to interpret its coefficients, and illustrate how well the model got rid of spatial autocorrelation in the data.
First, we create a little helper function that help speed up the analysis of residuals later on. It extracts the residuals, calculates a measure of their autocorrelation, plots the residuals, and creates a LISA map of them.
analyze_residuals <- function(model, data, weights, model_name) {
# Add residuals to data
data <- data |>
mutate(residuals = residuals(model))
# Calculate Moran's I
morans_i <- moran.test(data$residuals, weights, zero.policy = TRUE)
# Calculate LISA
local_morans <- localmoran(data$residuals, weights, zero.policy = TRUE)
# Add LISA to data
data <- data |>
mutate(
local_i = local_morans[, "Ii"],
local_i_p = local_morans[, "Pr(z != E(Ii))"]
)
# Create residuals map
breaks_res <- classIntervals(data$residuals, n = 7, style = "jenks")
res_map <- data |>
ggplot() +
geom_sf(aes(fill = residuals),
color = "gray90",
size = 0.1) +
scale_fill_gradientn(
colors = brewer.pal(7, "BuPu"),
breaks = round(breaks_res$brks, 1),
name = "Residuals",
guide = guide_colorbar(
direction = "horizontal",
title.position = "top",
label.position = "bottom",
barwidth = 15,
barheight = 0.5
)
) +
theme_minimal() +
theme(
plot.title = element_text(hjust = 0.5, size = 16, face = "bold"),
legend.position = "bottom"
) +
labs(
title = paste(model_name, "Model Residuals"),
subtitle = "Purple indicates over-prediction, Blue indicates under-prediction"
)
# Create LISA map
lisa_map <- data |>
ggplot() +
geom_sf(aes(fill = local_i), color = "gray70", size = 0.1) +
scale_fill_gradient2(
low = "blue", mid = "white", high = "red",
midpoint = 0,
name = "Local Moran's I"
) +
theme_minimal() +
theme(plot.title = element_text(hjust = 0.5, size = 16, face = "bold")) +
labs(
title = paste("Local Moran's I of", model_name, "Residuals"),
subtitle = "Spatial Clustering of Model Residuals"
)
return(list(
morans_i = morans_i,
res_map = res_map,
lisa_map = lisa_map
))
}Spatially Lagged X Model (SLX)
The main idea of SLX models is that characteristics of neighboring counties can affect the focal county. To this end, we include spatially lagged independent variables, i.e., neighboring counties’ average values for each independent variable.
\(y = X\beta + WX\theta + \varepsilon\)
Hence, this model includes the characteristics of neighboring counties but assumes no feedback effects through the dependent variable.
First, we create the spatially lagged x variables for each county. This takes the county’s neighboring values and weighs them by the continguency matrix. In our case, since we chose then queen method, it averages them as every neighboring county is assumed to have the same impact.
us_counties_child_pov_xlags <- us_counties_child_pov |>
mutate(
W_lnmanufacturing = lag.listw(counties_weights, lnmanufacturing),
W_lnretail = lag.listw(counties_weights, lnretail),
W_lnhealthss = lag.listw(counties_weights, lnhealthss),
W_lnconstruction = lag.listw(counties_weights, lnconstruction),
W_lnlesshs = lag.listw(counties_weights, lnlesshs),
W_lnunemployment = lag.listw(counties_weights, lnunemployment),
W_lnsinglemom = lag.listw(counties_weights, lnsinglemom),
W_lnuninsured = lag.listw(counties_weights, lnuninsured),
W_lnteenbirth = lag.listw(counties_weights, lnteenbirth),
W_lnincome_ratio = lag.listw(counties_weights, lnincome_ratio),
W_lnunmarried = lag.listw(counties_weights, lnunmarried),
W_lnblack = lag.listw(counties_weights, lnblack),
W_lnhispanic = lag.listw(counties_weights, lnhispanic)
)Then, we can include the lagged values in our already existing OLS model and fit the SLX model.
slx_formula <- update(formula(ols_mod),
. ~ . + W_lnmanufacturing + W_lnretail + W_lnhealthss +
W_lnconstruction + W_lnlesshs + W_lnunemployment +
W_lnsinglemom + W_lnuninsured + W_lnteenbirth +
W_lnincome_ratio + W_lnunmarried + W_lnblack + W_lnhispanic)
slx_mod <- lm(slx_formula, data = us_counties_child_pov_xlags)
slx_mod |> summary()
Call:
lm(formula = slx_formula, data = us_counties_child_pov_xlags)
Residuals:
Min 1Q Median 3Q Max
-26.7089 -3.6617 -0.1929 3.5190 23.9823
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -78.5000 7.2509 -10.826 < 2e-16 ***
lnmanufacturing -0.1553 0.3498 -0.444 0.657153
lnretail -2.3685 0.6648 -3.563 0.000379 ***
lnhealthss 1.2608 1.0471 1.204 0.228775
lnconstruction -2.0331 0.5031 -4.041 5.60e-05 ***
lnlesshs 9.2734 0.9139 10.147 < 2e-16 ***
lnunemployment 8.8444 1.0040 8.809 < 2e-16 ***
lnsinglemom 3.7411 0.5165 7.244 7.20e-13 ***
lnuninsured 7.8794 1.7304 4.553 5.74e-06 ***
lnteenbirth 0.4049 0.4624 0.876 0.381368
lnincome_ratio 8.0145 1.4890 5.383 8.60e-08 ***
lnunmarried 0.7275 0.2154 3.378 0.000751 ***
lnblack 0.1046 0.1931 0.542 0.587999
lnhispanic -0.2892 0.2182 -1.325 0.185249
W_lnmanufacturing -0.4297 0.4911 -0.875 0.381698
W_lnretail 0.2008 1.3627 0.147 0.882875
W_lnhealthss 3.2023 1.9218 1.666 0.095878 .
W_lnconstruction -2.4917 0.9553 -2.608 0.009200 **
W_lnlesshs -3.0703 1.3313 -2.306 0.021242 *
W_lnunemployment 2.5651 1.4374 1.785 0.074556 .
W_lnsinglemom 1.6053 1.0739 1.495 0.135206
W_lnuninsured 2.5635 2.1987 1.166 0.243849
W_lnteenbirth 0.7694 0.9271 0.830 0.406729
W_lnincome_ratio 1.8213 2.9486 0.618 0.536890
W_lnunmarried 0.7855 0.4976 1.579 0.114661
W_lnblack -0.2533 0.2470 -1.026 0.305139
W_lnhispanic -1.1449 0.3107 -3.685 0.000238 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 6.168 on 1395 degrees of freedom
Multiple R-squared: 0.6547, Adjusted R-squared: 0.6483
F-statistic: 101.7 on 26 and 1395 DF, p-value: < 2.2e-16In an SLX model, the interpretation of the coefficients is comparable to a normal OLS model. Note that the variables with suffix W do refer to neighboring counties’ values though.
In our case, we see significant positive impacts of lower levels of education, higher unemployment rates, single motherhood, a higher number of uninsured individuals, larger income ratios, and a higher share unmarried people; conversely, more jobs in retail lead to less child poverty. These effects are true for within the county at hand.
On the other hand, we see significant impacts of variables from surrounding counties: a smaller share of construction jobs in a neighboring counties is related to higher child poverty in the focal county. Also, higher levels of education in neighboring counties are related to more child poverty in the focal county – this might perhaps be related to lower educated people having moved to the focal county. Moreover, a lower share of Hispanx people in neighboring counties is significantly negatively correlated with child poverty.
Overall, the SLX model has slightly better fit than the OLS model (\(R^2_{SLX} = 0.65 > R^2_{OLS} = 0.64\)).
# Analyze residuals
slx_analysis <- analyze_residuals(slx_mod, us_counties_child_pov,
counties_weights, "SLX")
slx_analysis[[1]]
Moran I test under randomisation
data: data$residuals
weights: weights
Moran I statistic standard deviate = 5.4509, p-value = 2.506e-08
alternative hypothesis: greater
sample estimates:
Moran I statistic Expectation Variance
0.0872500352 -0.0007037298 0.0002603593 slx_analysis[[2]]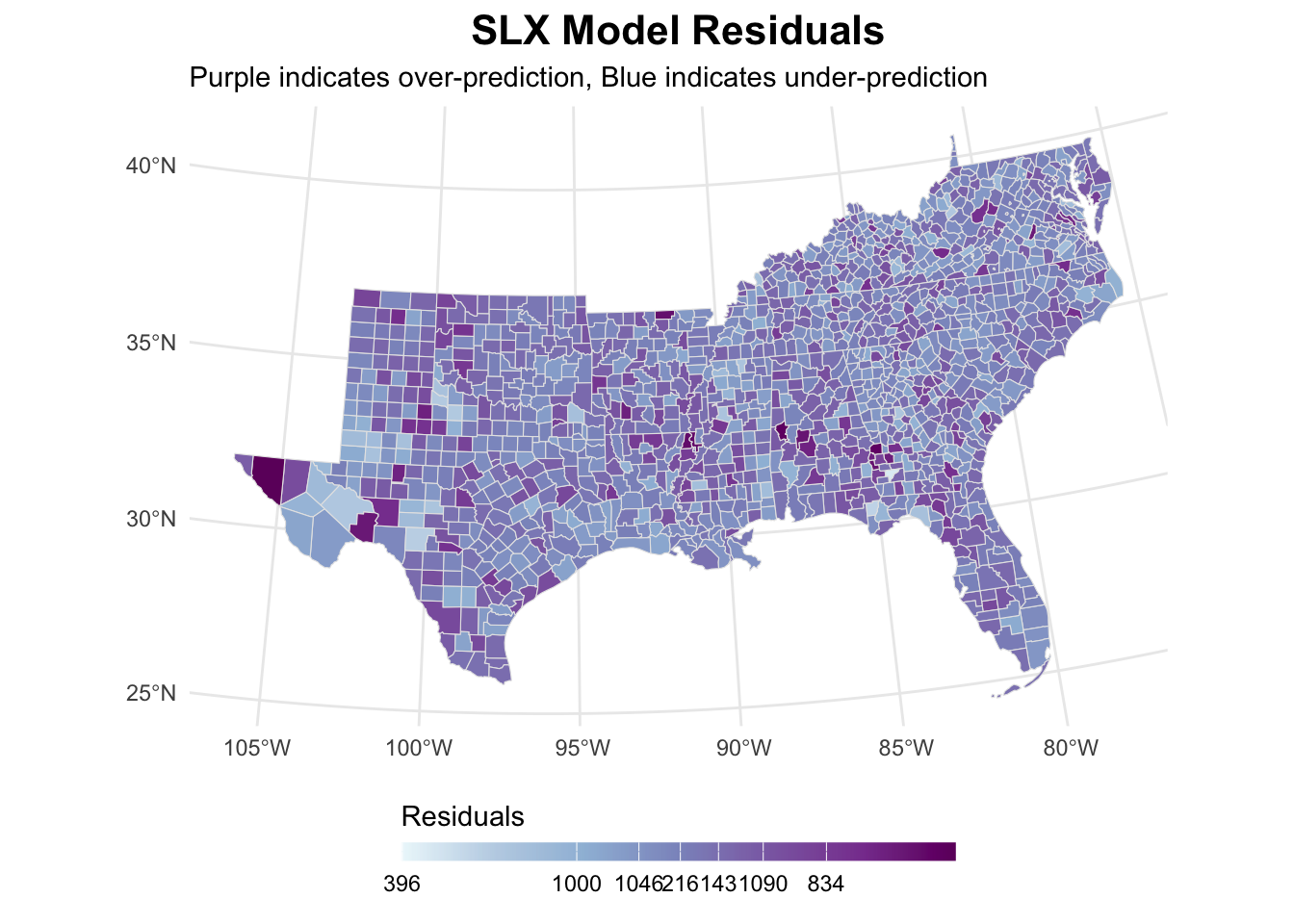
slx_analysis[[3]]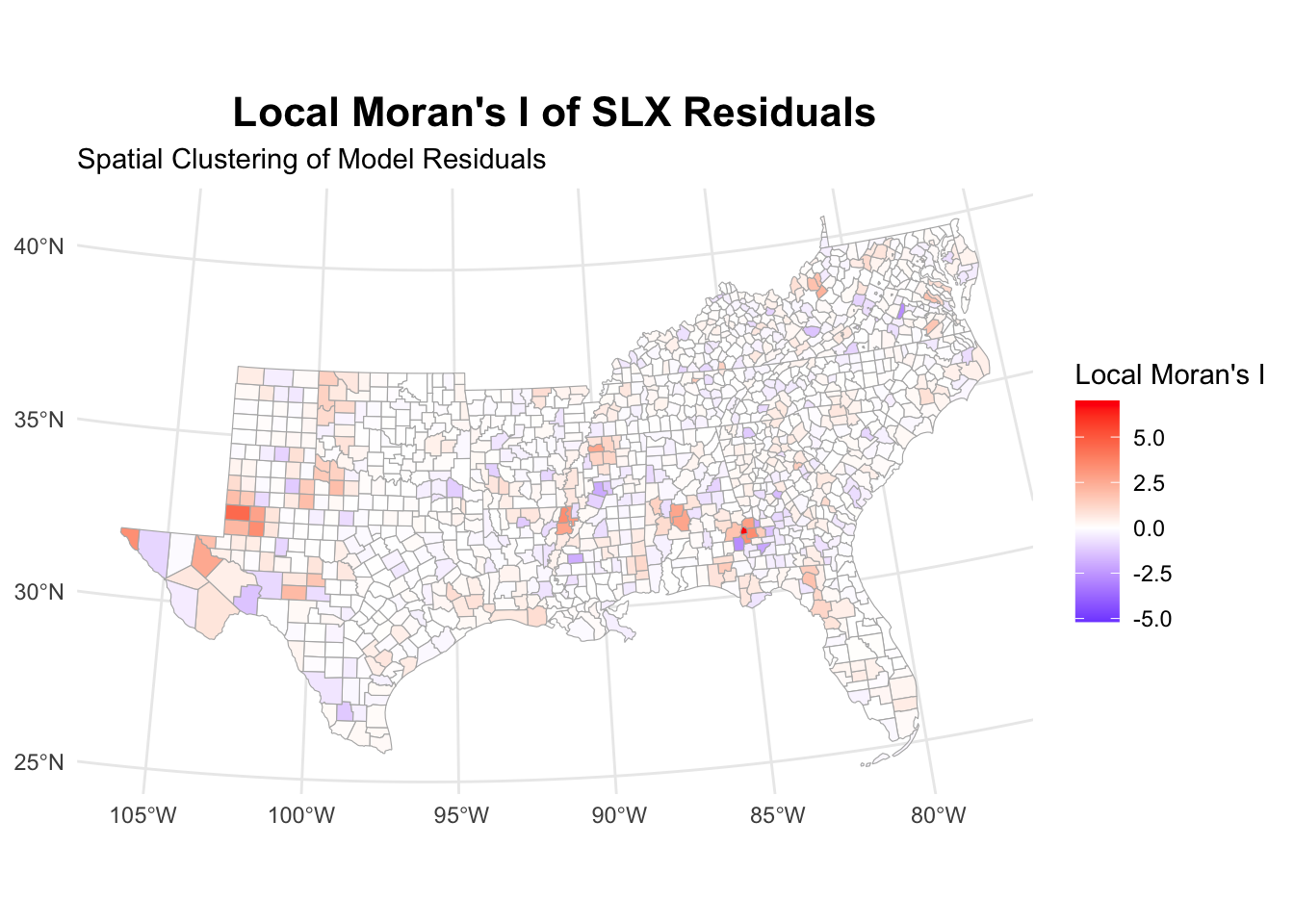
The SLX model has substantially reduced the autocorrelation of residuals. This is also reflected in the maps, showing lower clustering of residuals.
Spatial Autoregressive Model (SAR)
In SAR models, we include a lag of the outcome variable. Hence, we capture global feedback effects.
\[y = X\beta + \rho Wy + \varepsilon\]
sar_mod <- lagsarlm(formula(ols_mod),
data = us_counties_child_pov,
listw = counties_weights,
zero.policy = TRUE)
sar_mod |> summary()
Call:lagsarlm(formula = formula(ols_mod), data = us_counties_child_pov,
listw = counties_weights, zero.policy = TRUE)
Residuals:
Min 1Q Median 3Q Max
-27.86315 -3.66282 -0.22175 3.40291 25.37539
Type: lag
Coefficients: (asymptotic standard errors)
Estimate Std. Error z value Pr(>|z|)
(Intercept) -61.674252 4.135935 -14.9118 < 2.2e-16
lnmanufacturing -0.062467 0.249751 -0.2501 0.8024979
lnretail -2.306325 0.623649 -3.6981 0.0002172
lnhealthss 1.624842 0.918611 1.7688 0.0769267
lnconstruction -2.134674 0.466962 -4.5714 4.845e-06
lnlesshs 7.991435 0.652741 12.2429 < 2.2e-16
lnunemployment 9.391368 0.756741 12.4103 < 2.2e-16
lnsinglemom 3.805334 0.483234 7.8747 3.331e-15
lnuninsured 7.563558 1.040448 7.2695 3.608e-13
lnteenbirth 0.389173 0.437439 0.8897 0.3736471
lnincome_ratio 7.487934 1.407422 5.3203 1.036e-07
lnunmarried 0.819527 0.211263 3.8792 0.0001048
lnblack 0.096544 0.119175 0.8101 0.4178810
lnhispanic -0.796734 0.162257 -4.9103 9.093e-07
Rho: 0.18915, LR test value: 47.342, p-value: 5.9615e-12
Asymptotic standard error: 0.027199
z-value: 6.9542, p-value: 3.5467e-12
Wald statistic: 48.36, p-value: 3.5467e-12
Log likelihood: -4598.1 for lag model
ML residual variance (sigma squared): 37.435, (sigma: 6.1184)
Number of observations: 1422
Number of parameters estimated: 16
AIC: 9228.2, (AIC for lm: 9273.5)
LM test for residual autocorrelation
test value: 2.6239, p-value: 0.10527The SAR model reveals significant spatial dependence in the data, with a positive spatial autoregressive parameter (rho) of 0.189 that is highly significant (p < 0.001). This indicates meaningful spillover effects between neighboring counties. Moreover, the model shows improvement over OLS with a lower AIC (9228.2 vs 9273.5).
Key predictors remain similar to previous models, with education, unemployment, and insurance coverage showing strong effects. These cannot interpreted directly.
The residual autocorrelation test (p = 0.105) suggests the model has adequately captured the spatial structure in the data. However, these coefficients cannot be interpreted directly as marginal effects due to the spatial multiplier effect. The spatial mulitplier effect means that a neighboring county will not only affect the focal county (direct effect), but also other neighboring counties which will affect other counties etc. (indirect effects).
Rho is the spatial multiplier. This means that other counties’ outcome values do not only have a direct effect, but the indirect effects will result in \(1/(1-0.189) = 1.233\) times the focal counties y variable, hence a 23.3 percent increase of the y variable due to indirect effects (on average).
We can disentangle direct and indirect effects of neighboring counties’ child poverty on the coefficients using the impacts() function.
# Calculate impacts
sar_impacts <- impacts(sar_mod, listw = counties_weights)
sar_impactsImpact measures (lag, exact):
Direct Indirect Total
lnmanufacturing -0.06289157 -0.01414686 -0.07703844
lnretail -2.32201150 -0.52231444 -2.84432594
lnhealthss 1.63589351 0.36797871 2.00387222
lnconstruction -2.14919352 -0.48344067 -2.63263419
lnlesshs 8.04578917 1.80982387 9.85561304
lnunemployment 9.45524378 2.12686730 11.58211109
lnsinglemom 3.83121678 0.86179583 4.69301261
lnuninsured 7.61500264 1.71292253 9.32792517
lnteenbirth 0.39182036 0.08813627 0.47995663
lnincome_ratio 7.53886358 1.69579578 9.23465936
lnunmarried 0.82510083 0.18559860 1.01069942
lnblack 0.09720032 0.02186429 0.11906461
lnhispanic -0.80215281 -0.18043666 -0.98258947For unemployment, which shows the strongest effect, a 1 unit increase in the focal county is associated with a direct effect of 9.46 percentage points increase in child poverty within the same county. The indirect effect through spatial spillovers adds another 2.13 percentage points, leading to a total effect of 11.58 percentage points. This illustrates how unemployment’s impact ripples through the spatial system.
Some variables show negative associations with child poverty. The Hispanic population has a total reducing effect of -0.98 percentage points (-0.80 direct + -0.18 indirect). Retail and construction sectors also show poverty-reducing effects, with total impacts of -2.84 and -2.63 percentage points respectively.
Overall, the ratio of indirect to direct effects remains fairly consistent across variables at roughly 22-23 percent – which aligns with our spatial multiplier of 1.233. This consistent pattern suggests the spatial spillover process works similarly for different socioeconomic characteristics.
# Analyze residuals
sar_analysis <- analyze_residuals(sar_mod, us_counties_child_pov,
counties_weights, "SAR")
sar_analysis[[1]]
Moran I test under randomisation
data: data$residuals
weights: weights
Moran I statistic standard deviate = 1.2436, p-value = 0.1068
alternative hypothesis: greater
sample estimates:
Moran I statistic Expectation Variance
0.0193630758 -0.0007037298 0.0002603604 sar_analysis[[2]]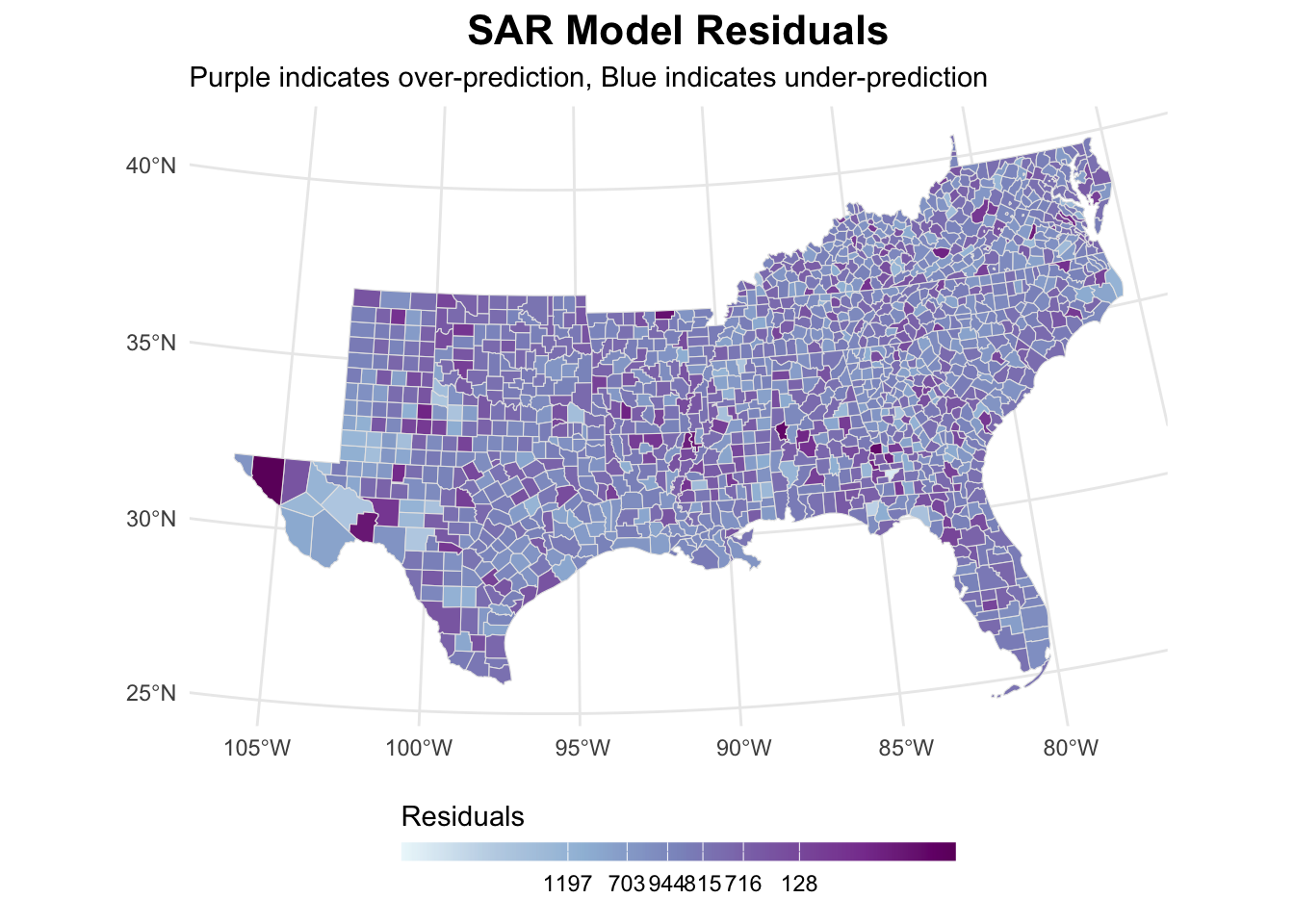
sar_analysis[[3]]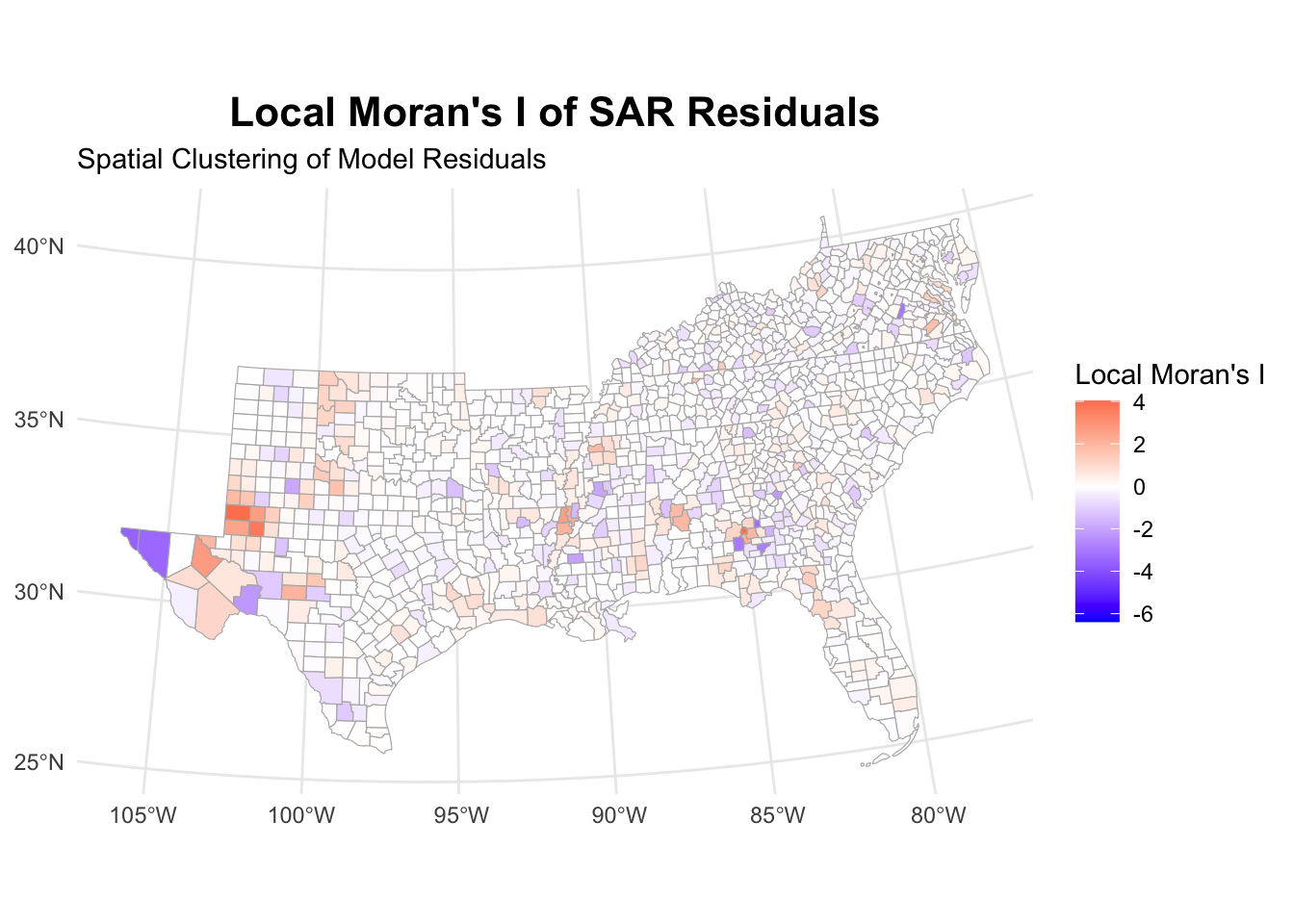
Again, the model took care of removing the autocorrelation within residuals.
Spatial Error Model (SEM)
The idea behind the spatial error model is that there might be things we can’t measure that affect the focal county and the neighboring ones. To solve this, we include an error term for the focal county and the neighboring counties. The assumption is that some clustered residuals are higher than expected and, therefore, there needs to be another missing variable that we cannot account for with our data. This can be captured in the spatial error term.
\[y = X\beta + u\]
with \(u = \lambda W u + \varepsilon\), the function of our unexplained error (\(\varepsilon\)) and our neighbors residual values.
# Fit SEM model
sem_mod <- errorsarlm(formula(ols_mod),
data = us_counties_child_pov,
listw = counties_weights,
zero.policy = TRUE)
sem_mod |> summary()
Call:errorsarlm(formula = formula(ols_mod), data = us_counties_child_pov,
listw = counties_weights, zero.policy = TRUE)
Residuals:
Min 1Q Median 3Q Max
-30.88707 -3.58264 -0.17312 3.55429 25.31482
Type: error
Coefficients: (asymptotic standard errors)
Estimate Std. Error z value Pr(>|z|)
(Intercept) -65.180265 4.476352 -14.5610 < 2.2e-16
lnmanufacturing -0.026076 0.281853 -0.0925 0.9262884
lnretail -2.324150 0.635991 -3.6544 0.0002578
lnhealthss 1.584146 0.968478 1.6357 0.1019011
lnconstruction -2.259206 0.481451 -4.6925 2.699e-06
lnlesshs 8.994277 0.720724 12.4795 < 2.2e-16
lnunemployment 10.616986 0.812173 13.0723 < 2.2e-16
lnsinglemom 3.610837 0.494996 7.2947 2.993e-13
lnuninsured 8.055363 1.198213 6.7228 1.782e-11
lnteenbirth 0.625491 0.445561 1.4038 0.1603693
lnincome_ratio 8.612597 1.435503 5.9997 1.977e-09
lnunmarried 0.750120 0.211483 3.5469 0.0003897
lnblack 0.199890 0.137718 1.4514 0.1466547
lnhispanic -0.836902 0.177821 -4.7064 2.521e-06
Lambda: 0.26118, LR test value: 39.277, p-value: 3.6767e-10
Asymptotic standard error: 0.038658
z-value: 6.7562, p-value: 1.4168e-11
Wald statistic: 45.646, p-value: 1.4168e-11
Log likelihood: -4602.133 for error model
ML residual variance (sigma squared): 37.412, (sigma: 6.1165)
Number of observations: 1422
Number of parameters estimated: 16
AIC: 9236.3, (AIC for lm: 9273.5)The spatial error parameter (lambda) of 0.26 is highly significant (p < 0.001), indicating substantial spatial correlation in unobserved factors affecting child poverty. This suggests that unmeasured characteristics that influence child poverty are spatially clustered.
Unemployment shows the strongest association with child poverty, where a 1 unit increase in unemployment corresponds to a 10.62 percentage point increase in child poverty. Education (less than high school) follows with nearly as large an effect at 8.99 percentage points. Other substantial effects include income inequality (8.61) and uninsured population (8.06), all highly significant.
The model shows negative associations with retail (-2.32), construction (-2.26), and Hispanic population (-0.84), suggesting these factors correspond with lower child poverty rates. Manufacturing shows no significant effect.
The model fit over OLS has improved, with an AIC of 9236.3, which improves upon both the OLS (AIC = 9273.5) and the SAR model (AIC = 9228.2). Unlike the SAR model, these coefficients can be interpreted directly as marginal effects since the spatial dependence is modeled through the error term rather than through a spatial lag of the dependent variable.
# Analyze residuals
sem_analysis <- analyze_residuals(sem_mod, us_counties_child_pov,
counties_weights, "SEM")
sem_analysis[[1]]
Moran I test under randomisation
data: data$residuals
weights: weights
Moran I statistic standard deviate = -0.2222, p-value = 0.5879
alternative hypothesis: greater
sample estimates:
Moran I statistic Expectation Variance
-0.0042888450 -0.0007037298 0.0002603314 sem_analysis[[2]]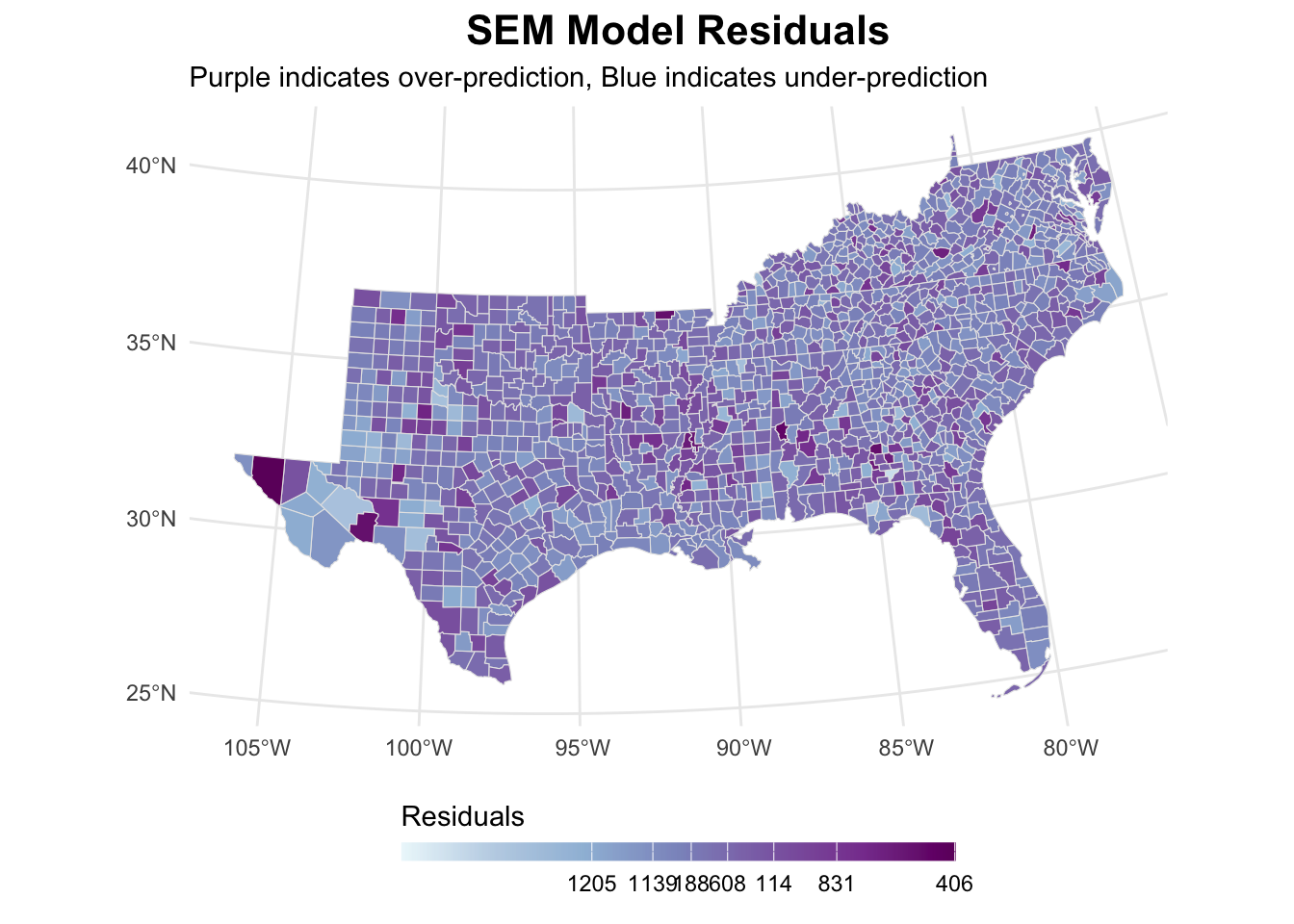
sem_analysis[[3]]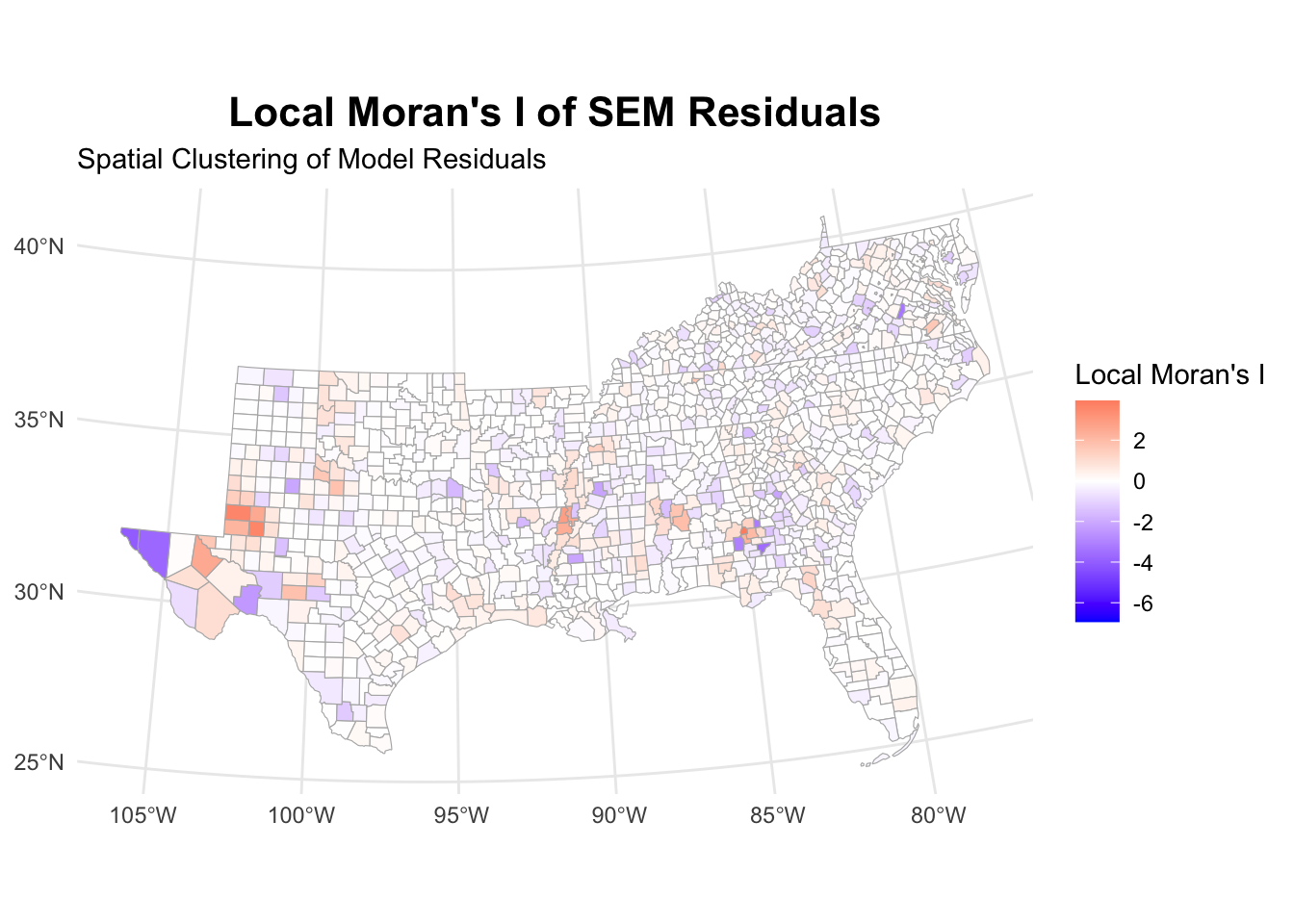
When looking at the residuals, we again see that the autocorrelation has disappeared.
Spatial Durbin Model (SDM)
The idea behind the Spatial Durbin Model is that both a neighboring county’s outcome variable (child poverty) and its neighbors’ characteristics matter. When we include a spatial lag of both the dependent variable (child poverty) and independent variables (like unemployment or education), we acknowledge that poverty in one county directly affects poverty in neighboring counties, and that the neighbors’ socioeconomic conditions also matter. This creates a complex web of relationships where changes ripple through the entire system of counties, not just immediate neighbors.
\[y = \rho Wy + X\beta + WX\theta + \varepsilon\]
# Fit SDM model
sdm_mod <- lagsarlm(formula(ols_mod),
data = us_counties_child_pov,
listw = counties_weights,
type = "mixed",
zero.policy = TRUE)
sdm_mod |> summary()
Call:lagsarlm(formula = formula(ols_mod), data = us_counties_child_pov,
listw = counties_weights, type = "mixed", zero.policy = TRUE)
Residuals:
Min 1Q Median 3Q Max
-28.47870 -3.61455 -0.14281 3.40597 24.61607
Type: mixed
Coefficients: (asymptotic standard errors)
Estimate Std. Error z value Pr(>|z|)
(Intercept) -61.87573 7.63588 -8.1033 4.441e-16
lnmanufacturing -0.14895 0.34116 -0.4366 0.6623924
lnretail -2.40941 0.64843 -3.7157 0.0002026
lnhealthss 1.17010 1.02144 1.1455 0.2519848
lnconstruction -1.92412 0.49098 -3.9189 8.894e-05
lnlesshs 9.41882 0.89166 10.5632 < 2.2e-16
lnunemployment 8.75420 0.97942 8.9381 < 2.2e-16
lnsinglemom 3.70807 0.50390 7.3587 1.859e-13
lnuninsured 7.70057 1.68787 4.5623 5.059e-06
lnteenbirth 0.36332 0.45101 0.8056 0.4204926
lnincome_ratio 7.95611 1.45234 5.4781 4.298e-08
lnunmarried 0.70193 0.21016 3.3399 0.0008379
lnblack 0.10974 0.18837 0.5826 0.5601890
lnhispanic -0.23646 0.21300 -1.1102 0.2669331
lag.lnmanufacturing -0.36707 0.47917 -0.7661 0.4436427
lag.lnretail 0.88573 1.33211 0.6649 0.5061108
lag.lnhealthss 2.45355 1.87706 1.3071 0.1911722
lag.lnconstruction -1.61152 0.94151 -1.7116 0.0869647
lag.lnlesshs -4.68249 1.33181 -3.5159 0.0004383
lag.lnunemployment 0.19498 1.46563 0.1330 0.8941628
lag.lnsinglemom 0.42756 1.06259 0.4024 0.6874061
lag.lnuninsured 0.44987 2.17984 0.2064 0.8364979
lag.lnteenbirth 0.53262 0.90479 0.5887 0.5560824
lag.lnincome_ratio -0.28031 2.89729 -0.0968 0.9229248
lag.lnunmarried 0.55941 0.48719 1.1482 0.2508719
lag.lnblack -0.24548 0.24086 -1.0192 0.3081207
lag.lnhispanic -0.88969 0.30669 -2.9010 0.0037202
Rho: 0.22223, LR test value: 30.618, p-value: 3.1417e-08
Asymptotic standard error: 0.039302
z-value: 5.6543, p-value: 1.5644e-08
Wald statistic: 31.972, p-value: 1.5644e-08
Log likelihood: -4575.988 for mixed model
ML residual variance (sigma squared): 36.194, (sigma: 6.0161)
Number of observations: 1422
Number of parameters estimated: 29
AIC: 9210, (AIC for lm: 9238.6)
LM test for residual autocorrelation
test value: 7.7435, p-value: 0.0053905The SDM results reveal significant spatial dependence (rho = 0.222), creating a multiplier effect where total impacts are 28.5% larger than direct effects due to spatial feedback through the system.
The model shows the best fit among our specifications with the so-far lowest AIC (9210.0), though significant residual autocorrelation suggests some spatial patterns remain uncaptured.
Again, like in the SAR model, we need to calculate impacts to properly disentangle the effects.
# Calculate impacts
sdm_impacts <- impacts(sdm_mod, listw = counties_weights)
sdm_impactsImpact measures (mixed, exact):
Direct Indirect Total
lnmanufacturing -0.1661423 -0.4973179 -0.6634602
lnretail -2.3943613 0.4353253 -1.9590359
lnhealthss 1.2866639 3.3723469 4.6590109
lnconstruction -2.0117092 -2.5341482 -4.5458574
lnlesshs 9.3075955 -3.2179765 6.0896190
lnunemployment 8.8461390 2.6600404 11.5061794
lnsinglemom 3.7618310 1.5554503 5.3172812
lnuninsured 7.7934022 2.6858089 10.4792111
lnteenbirth 0.3896627 0.7622677 1.1519304
lnincome_ratio 8.0200186 1.8489412 9.8689598
lnunmarried 0.7326561 0.8890688 1.6217249
lnblack 0.1002384 -0.2747698 -0.1745313
lnhispanic -0.2769393 -1.1709869 -1.4479261Here, unemployment shows the strongest total effect (11.51), combining a substantial direct effect (8.85) with positive spillovers (2.66), indicating that high unemployment affects poverty both within and across county lines.
The uninsured rate and income inequality follow similar patterns, with total effects of 10.48 and 9.87 respectively, both showing positive direct and indirect effects. This suggests these social challenges create regional, not just local, poverty impacts.
Education (less than high school) presents an interesting case with a strong positive direct effect (9.31) but negative indirect effect (-3.22), yielding a moderate total effect (6.09). This might be in line with what we saw in an earlier model, where higher education in surrounding counties had a positive effect on child poverty, suggesting that if a county is surrounded by better educated counties, the effect of more uneducated individuals in a county is more pronounced.
Construction jobs shows consistently negative effects (total -4.55), reducing poverty both directly (-2.01) and through spillovers (-2.53). The health sector demonstrates positive spillovers (3.37) that exceed its direct effect (1.29), suggesting regional importance of healthcare access. However, this might be mediated by other, unobserved variables.
The Hispanic population shows negative effects both directly (-0.28) and through spillovers (-1.17), while manufacturing’s impact remains relatively modest throughout.
These impacts, combined with the significant spatial parameter (ρ = 0.222), suggest child poverty is shaped by both local conditions and regional socioeconomic patterns.
# Analyze residuals
sdm_analysis <- analyze_residuals(sdm_mod, us_counties_child_pov,
counties_weights, "SDM")
sdm_analysis[[1]]
Moran I test under randomisation
data: data$residuals
weights: weights
Moran I statistic standard deviate = -0.35901, p-value = 0.6402
alternative hypothesis: greater
sample estimates:
Moran I statistic Expectation Variance
-0.0064963755 -0.0007037298 0.0002603470 sdm_analysis[[2]]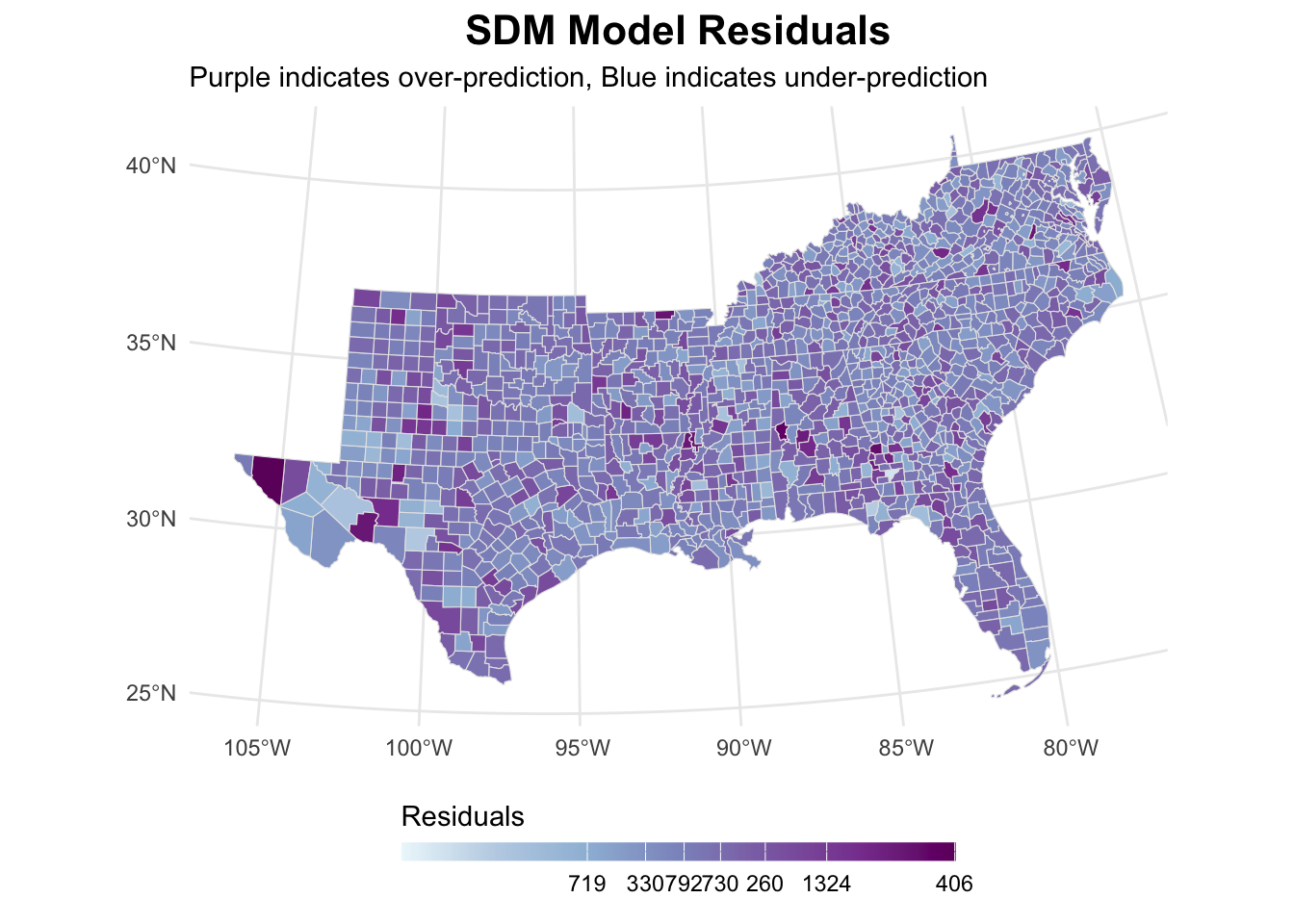
sdm_analysis[[3]]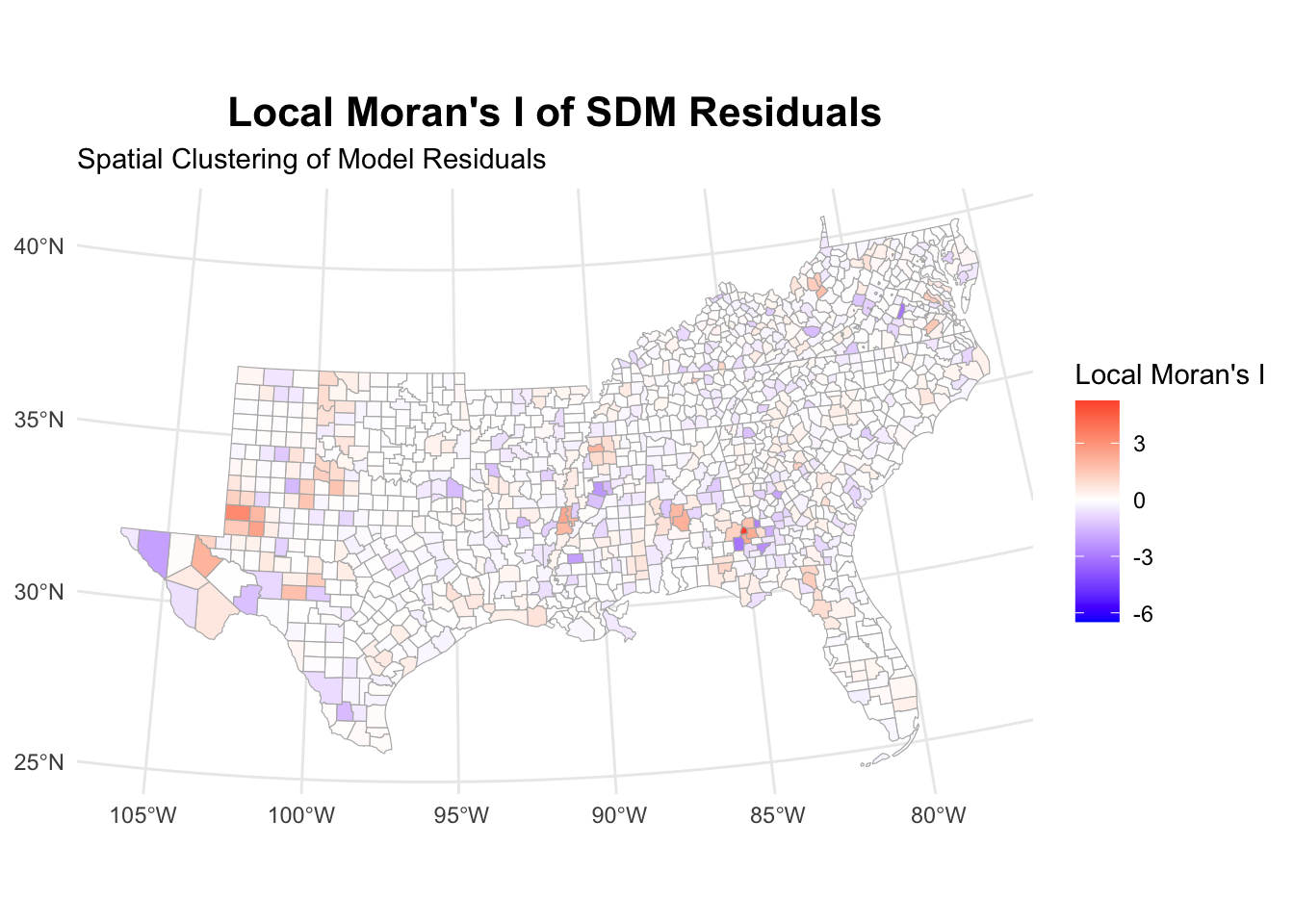
While the model diagnostics suggest that there is still some clustering of residuals, these are not visible in Moran’s I. LISA shows some clusters, but far fewer than with the normal OLS model.
Spatial Durbin Error Model (SDEM)
The idea behind the Spatial Durbin Error Model is that while neighboring counties’ characteristics matter for the focal county’s outcome variable (child poverty) and independent variablies (e.g., unemployment rates or education levels), the spillover effects remain local rather than rippling through the system. At the same time, we recognize that there are unmeasured factors – things we can’t capture in our data – that might be spatially clustered. For instance, local policies or cultural factors might affect groups of neighboring counties similarly.
This model combines the local spillover effects from measured variables with the spatial patterns in unmeasured factors, but without creating system-wide feedback loops which would be introduced by including lagged outcome variables.
\[y = X\beta + WX\theta + u, \quad \text{with }u = \lambda Wu + \varepsilon\]
# Fit SDEM model
sdem_mod <- errorsarlm(formula(ols_mod),
data = us_counties_child_pov,
listw = counties_weights,
etype = "emixed",
zero.policy = TRUE)
summary(sdem_mod)
Call:errorsarlm(formula = formula(ols_mod), data = us_counties_child_pov,
listw = counties_weights, etype = "emixed", zero.policy = TRUE)
Residuals:
Min 1Q Median 3Q Max
-28.6721 -3.6422 -0.1377 3.4005 24.2593
Type: error
Coefficients: (asymptotic standard errors)
Estimate Std. Error z value Pr(>|z|)
(Intercept) -77.65452 8.27088 -9.3889 < 2.2e-16
lnmanufacturing -0.16297 0.32928 -0.4949 0.6206544
lnretail -2.41241 0.64742 -3.7262 0.0001944
lnhealthss 1.26487 1.00127 1.2633 0.2064943
lnconstruction -2.02703 0.48453 -4.1835 2.870e-05
lnlesshs 9.28410 0.86365 10.7498 < 2.2e-16
lnunemployment 8.88366 0.94956 9.3556 < 2.2e-16
lnsinglemom 3.78925 0.50105 7.5627 3.952e-14
lnuninsured 7.75777 1.62914 4.7619 1.918e-06
lnteenbirth 0.39410 0.44924 0.8773 0.3803482
lnincome_ratio 8.05933 1.44133 5.5916 2.250e-08
lnunmarried 0.73784 0.21207 3.4792 0.0005029
lnblack 0.10365 0.18164 0.5706 0.5682519
lnhispanic -0.30944 0.20608 -1.5015 0.1332159
lag.lnmanufacturing -0.44991 0.50452 -0.8918 0.3725237
lag.lnretail 0.44124 1.43424 0.3076 0.7583533
lag.lnhealthss 2.78797 2.00880 1.3879 0.1651742
lag.lnconstruction -2.27504 1.00932 -2.2540 0.0241938
lag.lnlesshs -2.84773 1.36600 -2.0847 0.0370941
lag.lnunemployment 2.59073 1.48527 1.7443 0.0811092
lag.lnsinglemom 1.25438 1.12119 1.1188 0.2632294
lag.lnuninsured 2.69489 2.22843 1.2093 0.2265382
lag.lnteenbirth 0.70693 0.98426 0.7182 0.4726158
lag.lnincome_ratio 1.58178 3.11207 0.5083 0.6112619
lag.lnunmarried 0.76935 0.52169 1.4747 0.1402841
lag.lnblack -0.21954 0.25089 -0.8750 0.3815547
lag.lnhispanic -1.12810 0.32330 -3.4893 0.0004843
Lambda: 0.21241, LR test value: 26.945, p-value: 2.0934e-07
Asymptotic standard error: 0.039757
z-value: 5.3428, p-value: 9.1524e-08
Wald statistic: 28.545, p-value: 9.1524e-08
Log likelihood: -4577.825 for error model
ML residual variance (sigma squared): 36.317, (sigma: 6.0264)
Number of observations: 1422
Number of parameters estimated: 29
AIC: 9213.6, (AIC for lm: 9238.6)With SDEM, we can interpret coefficients directly since there’s no spatial lag of the dependent variable and spatial patterns in unobservables are captured by the error term. We see significant spatial error dependence (lambda = 0.212, p < 0.001). This indicates important unobserved spatial patterns in child poverty. Unlike the SDM, the SDEM assumes only local spillovers without global feedback effects.
The direct effects show familiar patterns: less than high school education (9.28), unemployment (8.88), income ratio (8.06), and uninsured population (7.76) strongly predict higher child poverty. Retail (-2.41) and construction (-2.03) sectors show poverty-reducing effects.
The spatial lags reveal local spillovers: Hispanic population in neighboring counties has a significant negative association (-1.13) with local poverty. Construction (-2.28) and education (-2.85) in neighboring counties also show significant negative spillovers. There’s a marginally significant positive spillover from neighboring unemployment (2.59, p < 0.10).
The model improves upon OLS (AIC 9238.6 vs 9213.6) but performs slightly worse than the SDM (AIC 9210.0). This suggests that global spillovers might be important.
# Analyze residuals
sdem_analysis <- analyze_residuals(sdem_mod, us_counties_child_pov,
counties_weights, "SDEM")
sdem_analysis[[1]]
Moran I test under randomisation
data: data$residuals
weights: weights
Moran I statistic standard deviate = -0.019692, p-value = 0.5079
alternative hypothesis: greater
sample estimates:
Moran I statistic Expectation Variance
-0.0010214709 -0.0007037298 0.0002603478 sdem_analysis[[2]]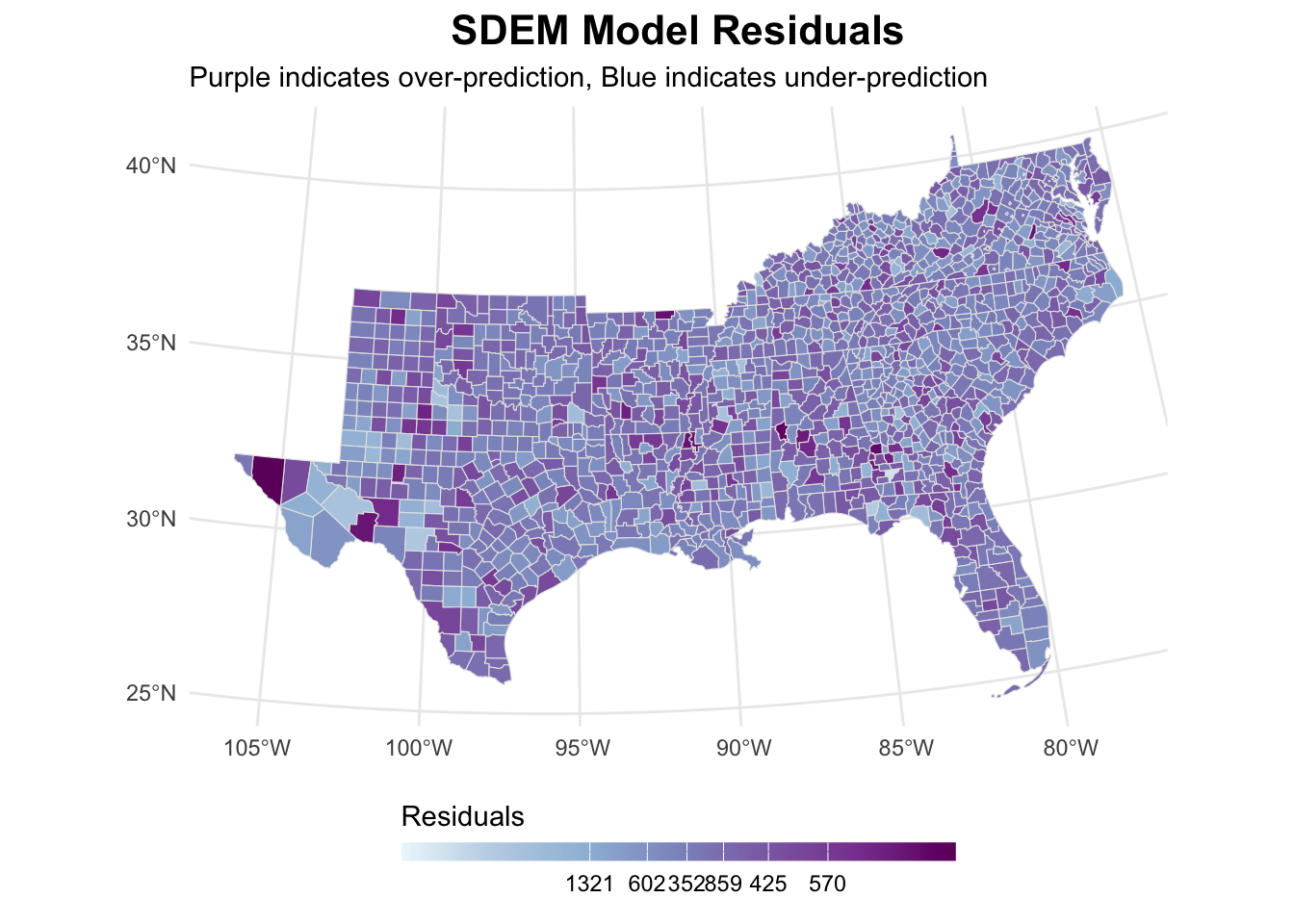
sdem_analysis[[3]]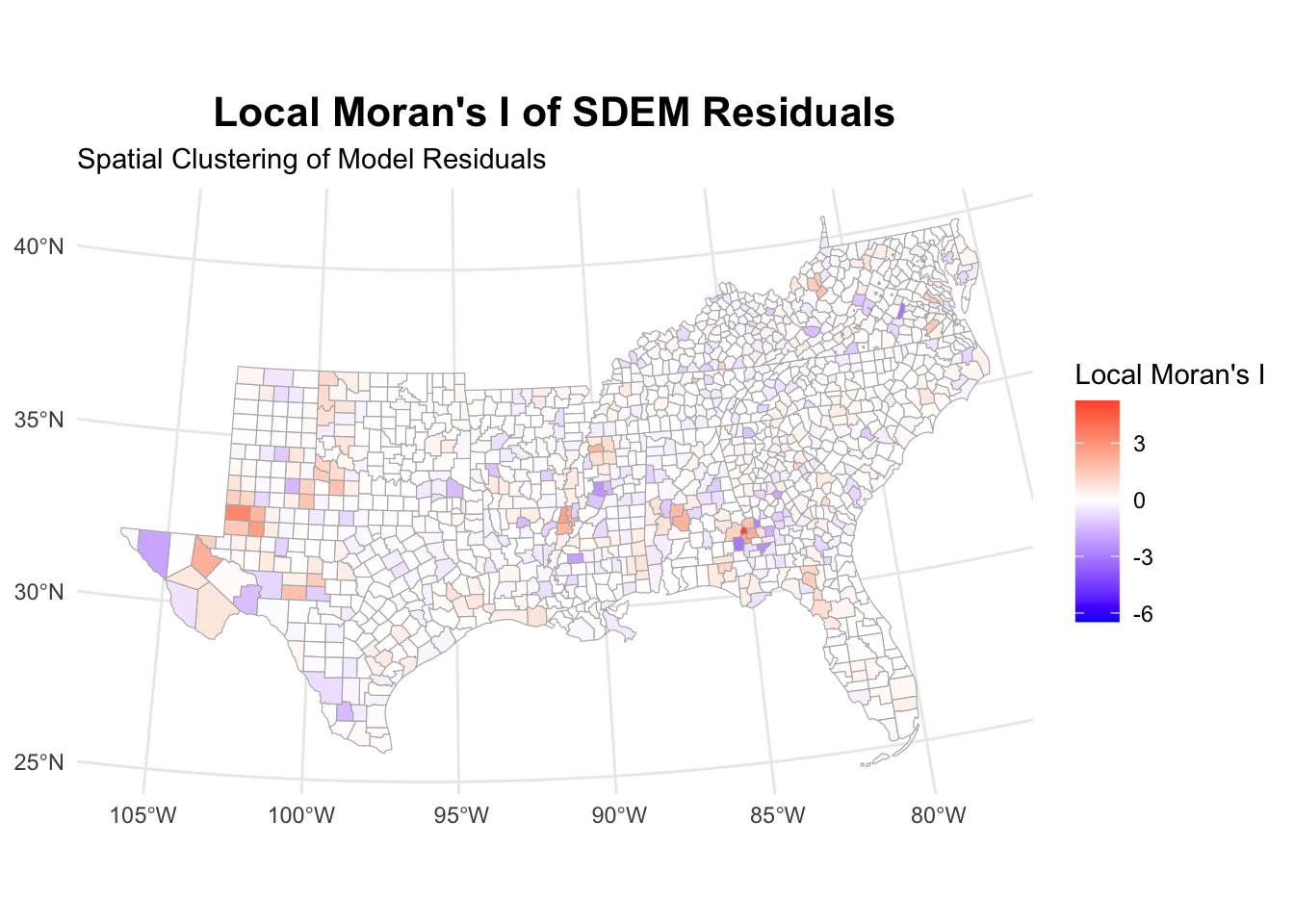
Again, autocorrelation within the residuals is removed. Yet, the LISA map shows some clustering which is very much comparable to the prior models.
Model comparison and selection
All the models delivered fairly similar results and performed better than mere OLS with no spatial component. But which one performed best? For model choice we have two approaches at our hands: comparing model fit using AIC and
The following chunk calculates the Akaike Information Criterion for all 6 models. This provides a measure of fit. Lower is better. Here, SDM and SDEM both perform very well and are therefore preferable. Using one of the two Durbin models is also in line with LeSage (2014). He basically advocates for using SDEMs most of the time and, if theoretically warranted, switching to SDMs.
models_comparison <- tibble(
Model = c("OLS", "SLX", "SAR", "SEM", "SDM", "SDEM"),
AIC = c(AIC(ols_mod), AIC(slx_mod), AIC(sar_mod),
AIC(sem_mod), AIC(sdm_mod), AIC(sdem_mod))
) |>
arrange(AIC)Using one of the two Durbin models is also in line with LeSage (2014). He basically advocates for using SDEMs most of the time and, if theoretically warranted, switching to SDMs. Given they show both good performance in terms of fit and the SDEM is comparably straight-forwardly interpretable, you should opt for the SDEM model here.
Another way would be to use a LaGrange Multiplier test. Here, we would focus on the models that are statistically significant and follow Anselin’s algorithm:
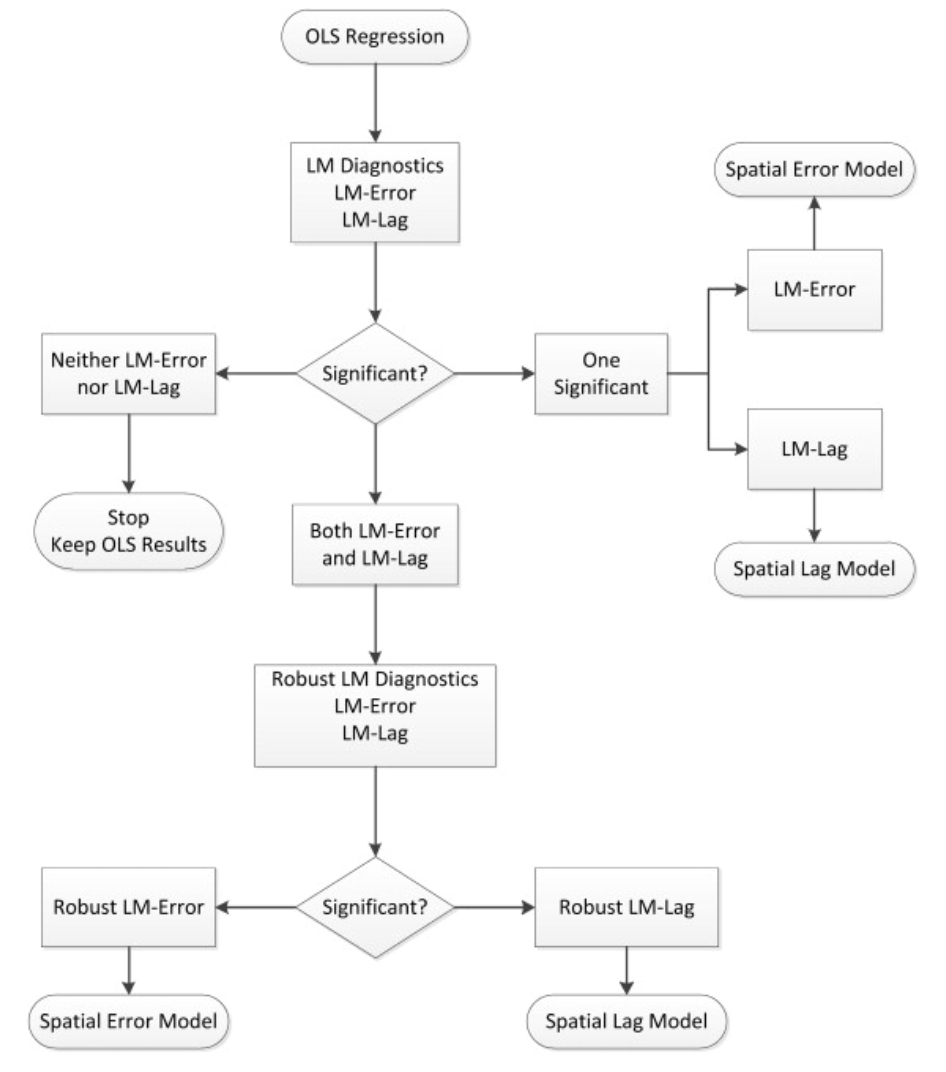
Basically, you check which models show the best significant results – lag or error – and then choose accordingly. Here, lag models seem to perform best.
lm_tests <- lm.RStests(ols_mod, counties_weights, test = "all")
print(lm_tests)
Rao's score (a.k.a Lagrange multiplier) diagnostics for spatial
dependence
data:
model: lm(formula = x2016_child_poverty ~ lnmanufacturing + lnretail +
lnhealthss + lnconstruction + lnlesshs + lnunemployment + lnsinglemom +
lnuninsured + lnteenbirth + lnincome_ratio + lnunmarried + lnblack +
lnhispanic, data = us_counties_child_pov)
test weights: counties_weights
RSerr = 40.289, df = 1, p-value = 2.19e-10
Rao's score (a.k.a Lagrange multiplier) diagnostics for spatial
dependence
data:
model: lm(formula = x2016_child_poverty ~ lnmanufacturing + lnretail +
lnhealthss + lnconstruction + lnlesshs + lnunemployment + lnsinglemom +
lnuninsured + lnteenbirth + lnincome_ratio + lnunmarried + lnblack +
lnhispanic, data = us_counties_child_pov)
test weights: counties_weights
RSlag = 50.293, df = 1, p-value = 1.324e-12
Rao's score (a.k.a Lagrange multiplier) diagnostics for spatial
dependence
data:
model: lm(formula = x2016_child_poverty ~ lnmanufacturing + lnretail +
lnhealthss + lnconstruction + lnlesshs + lnunemployment + lnsinglemom +
lnuninsured + lnteenbirth + lnincome_ratio + lnunmarried + lnblack +
lnhispanic, data = us_counties_child_pov)
test weights: counties_weights
adjRSerr = 4.7468, df = 1, p-value = 0.02935
Rao's score (a.k.a Lagrange multiplier) diagnostics for spatial
dependence
data:
model: lm(formula = x2016_child_poverty ~ lnmanufacturing + lnretail +
lnhealthss + lnconstruction + lnlesshs + lnunemployment + lnsinglemom +
lnuninsured + lnteenbirth + lnincome_ratio + lnunmarried + lnblack +
lnhispanic, data = us_counties_child_pov)
test weights: counties_weights
adjRSlag = 14.751, df = 1, p-value = 0.0001227
Rao's score (a.k.a Lagrange multiplier) diagnostics for spatial
dependence
data:
model: lm(formula = x2016_child_poverty ~ lnmanufacturing + lnretail +
lnhealthss + lnconstruction + lnlesshs + lnunemployment + lnsinglemom +
lnuninsured + lnteenbirth + lnincome_ratio + lnunmarried + lnblack +
lnhispanic, data = us_counties_child_pov)
test weights: counties_weights
SARMA = 55.04, df = 2, p-value = 1.117e-12Further links
- A tutorial dealing with Moran’s I
- Chris Gentry’s tutorial
- A comprehensive tutorial that includes spatial regression analysis
- The spatialreg package’s website
References
LeSage, James P. 2014. “What Regional Scientists Need to Know About Spatial Econometrics.” SSRN Electronic Journal.
Footnotes
I found this data while browsing the web for inspiration in this excellent tutorial. I use more States in my example, different code, and explain it a bit differently, yet I would like to extend my gratitude to Prof. Gentry for the data↩︎